It started with a tweet, how did it end up like this?
Use Ansible to build a 10,041 node K8S cluster in AWS, deploy a single the HelloWorld container, then tear them down at the end of the script.
— Dan Linder (@dan_linder) May 13, 2020
I've had a YouTube channel since 2006—back when YouTube was a plucky upstart battling against Google Video (not Google Videos) and Vimeo. I started livestreaming a couple months ago on a whim, and since that time I've gained more subscribers than I had gained between 2006-2020!
So it seems fitting that I find some nerdy way to celebrate. After all, if Coline Furze can celebrate his milestones with ridiculous fireworks displays, I can do ... something?
First, the video—scroll past it for a little more detail in the blog post:
Know thy limits
Currently, the Kubernetes documentation provides the following guidelines for 'large cluster' limits:
- No more than 5000 nodes
- No more than 150000 total pods
- No more than 300000 total containers
- No more than 100 pods per node
I've had to deal with a few large clusters—though none with more than around 100 nodes and 5-6,000 pods total—and I know things can start getting... interesting.
Also, the 'no more than 5000 nodes' thing already rules out Dan's first suggestion, "10,041 nodes in a K8s cluster", so I had to shift targets appropriately. Plus, even one hour with 10,041 t3 EC2 nodes would cost over $100 (plus the hourly cost of an EKS control plane).
So that was right out.
Instead, my target shifted to 10,000 Pods. That seemed an achievable target! At a limit of 100 Pods per node, assuming I could run pods that had miniscule RAM and CPU requirements, that would put me around 100 nodes to run 10,000 pods (yay, easy math!).
And if I could get it all done on AWS t3.micro instances, I'd be golden, since I could run them for up to 7 hours before I hit the Free Tier Limits! If not, it would be around $1.04/hour for 100 t3.micro instances.
Luckily for me, my plan of running 100 instances puts me right at the limit for an EKS Node Group. Yay for good luck!
The game plan: Automation
There's no way you can quickly build and tear down hundreds of nodes and thousands of Pods without automation, so I leaned on three familiar tools:
- CloudFormation (though I could've used Terraform instead)
- Ansible (to manage the CloudFormation templates and deploy into K8s)
- Kubernetes/EKS (to run the Pods)
I blatantly ripped off the CloudFormation EKS cluster build example from chapter 5 of Ansible for Kubernetes, then modified it to build 100 t3.micro instances in a single EKS Node Group.
Hitting AWS Service Limits
I deployed the CloudFormation templates and waited the customary 15 minutes for an EKS cluster to get bootstrapped. (Aside: Does Amazon bill you for the half an hour an EKS cluster gets set up and destroyed when you are testing things with EKS?).
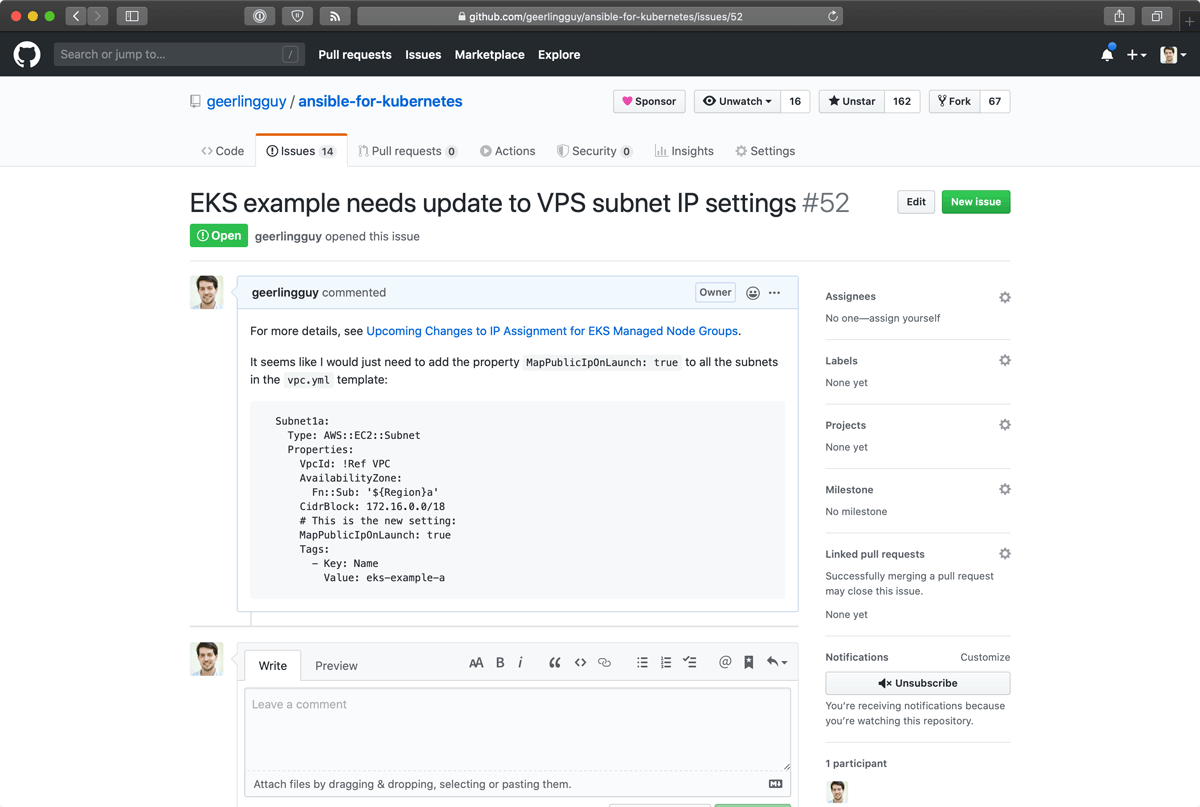
And, of course, I found a bug in my own code, stemming from a very recent Changes to IP Assignment for EKS Managed Node Groups. So I went over to my book repo and filed an issue. I'll take care of it later:
Then, after 18 instances of the 100-node Node Group had booted, I got the dreaded ROLLBACK_IN_PROGRESS message from CloudFormation:
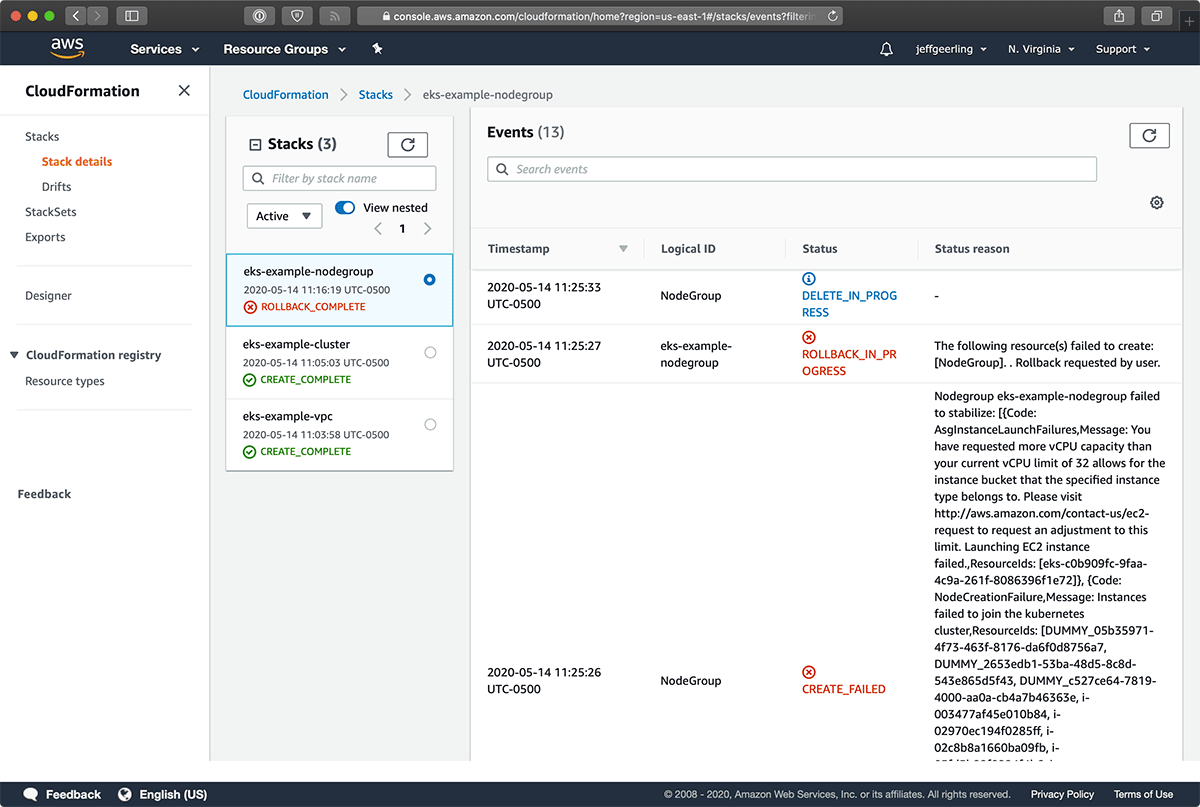
D'oh! I filed a support request for a service limit increase, and waited a bit:
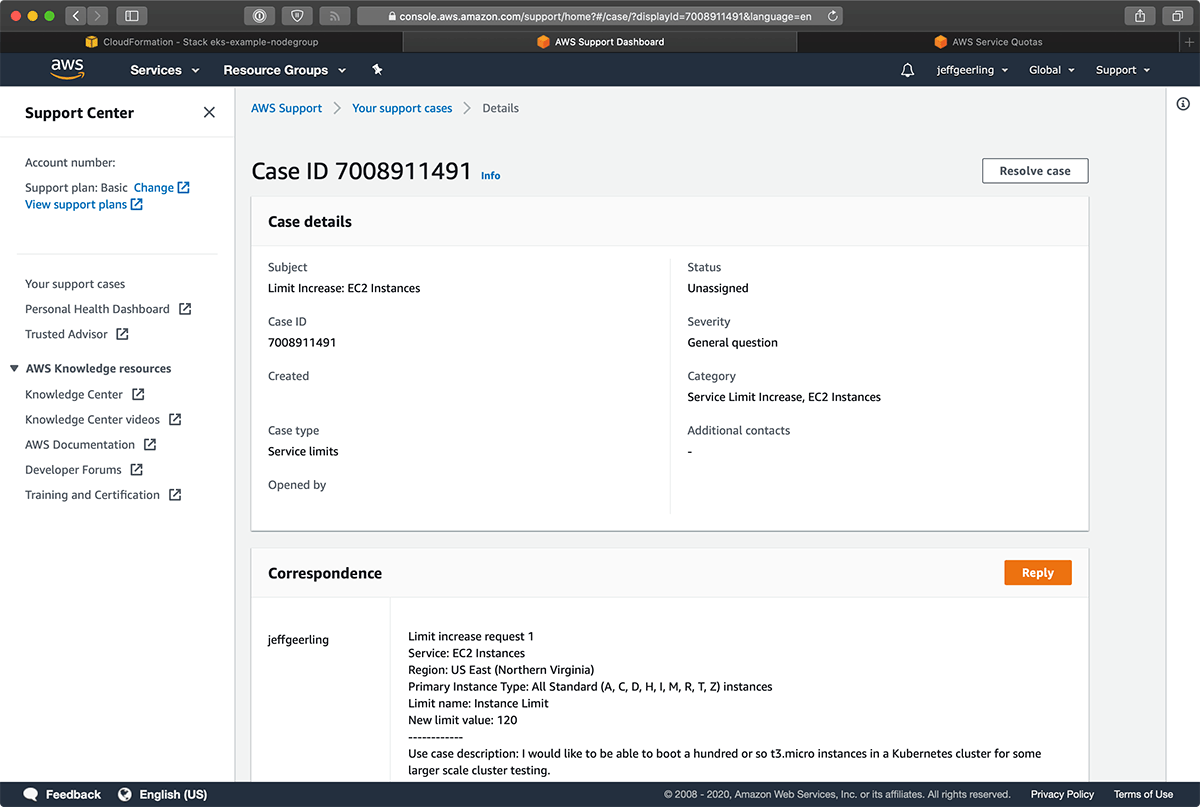
I waited another 15 minutes for an EKS cluster to boot, then it started creating EKS Node Group instances.
This time, it worked!
I had to grab the kube-config from EKS and set the context:
$ aws eks --region us-east-1 --profile jeffgeerling update-kubeconfig --name eks-example --kubeconfig ~/.kube/eks-example
$ export KUBECONFIG=~/.kube/eks-example
$ kubectl get nodes | tail -n +2 | wc -l
60
Drat. I had forgotten that the Service Limit Increase is for vCPUs, not 'EC2 Instances', even though that's what it says when you're requesting the increase! So back on the support train: I decided to request a new limit of 400 vCPUs:
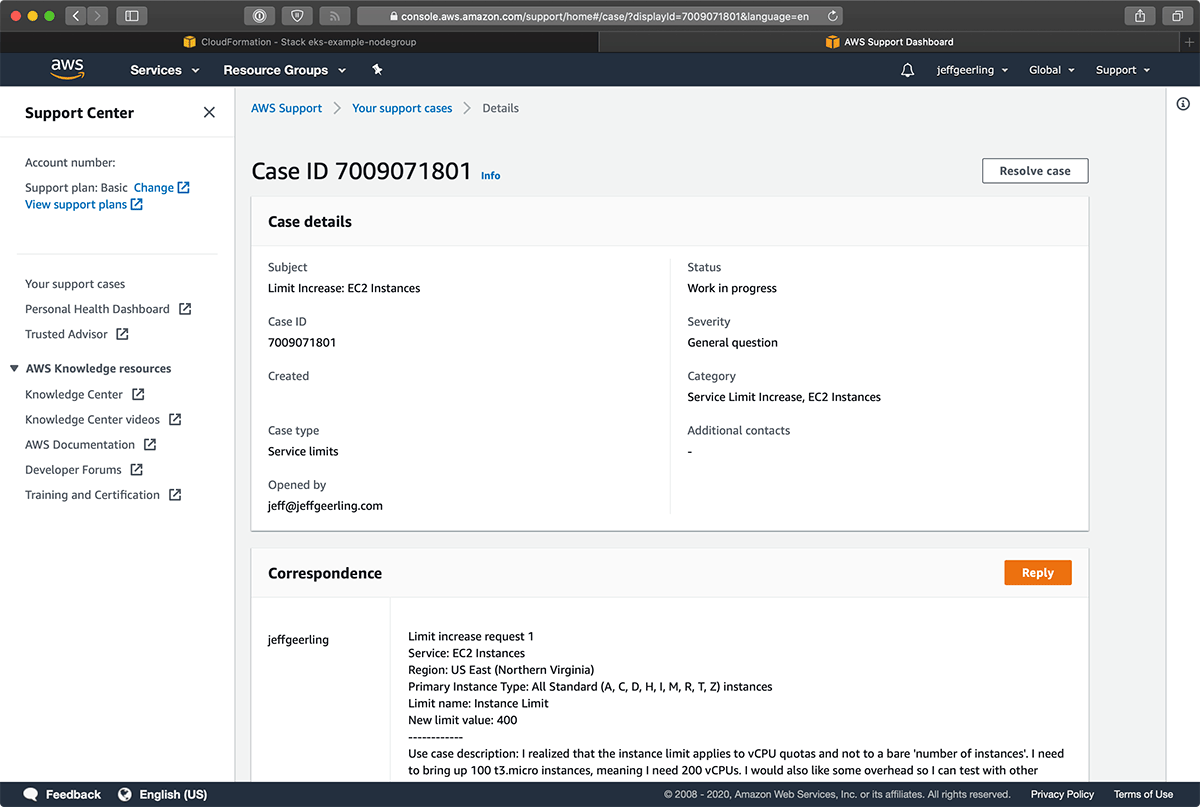
After another half hour or so, I was granted 300 vCPUs, but that would still be enough to run 100 2 vCPU t3.micro instances, so I was happy.
Deploying the pods: one per YouTube subscriber
Now it was time to see if I could somehow deploy 10,000 pods to my fresh 100 node cluster.
I went ahead and applied the hello-node example deployment from the Kubernetes hello-minikube docs (using the image k8s.gcr.io/echoserver:1.4).
Then I changed the replicas from 1 to 10000, and sat back and waited for glorious victory!
The pods started populating (this took about 10 minutes—gif is sped up quite a bit):
But, the count of Pod resources reached 10,000, I noticed most of them were in Pending status. What was wrong? Checking on the hello-node deployment, I had only 198 running/available pods:
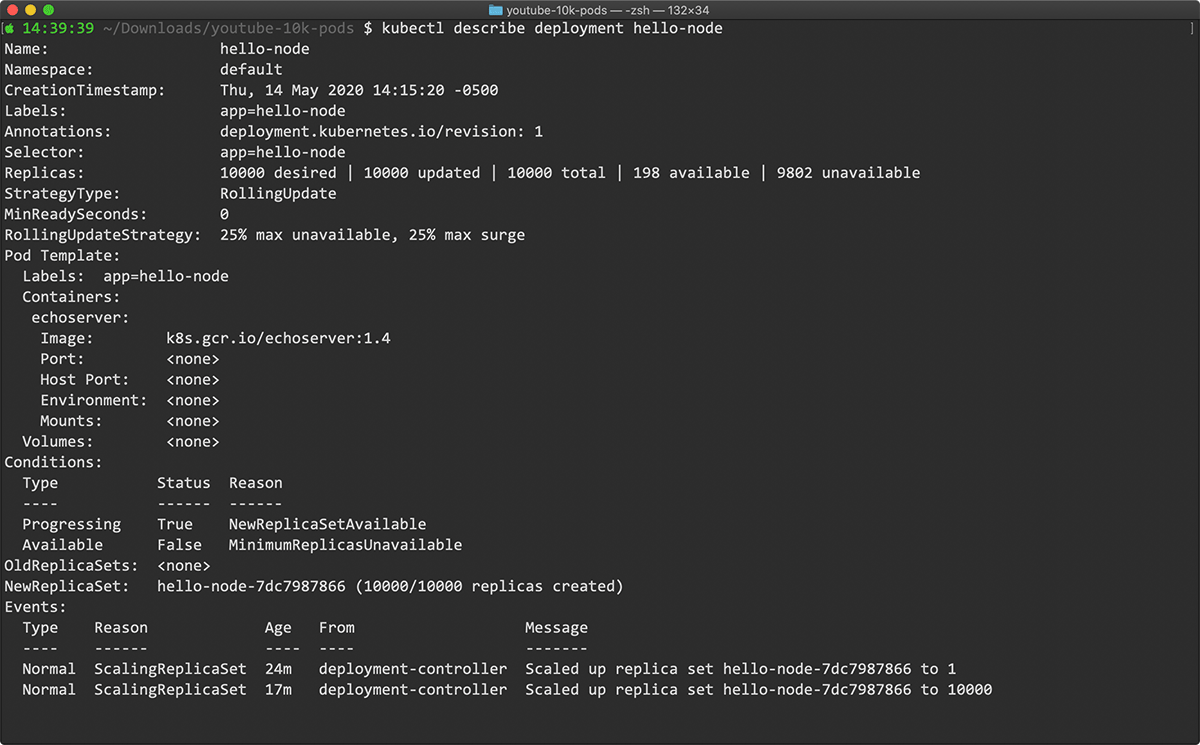
Why am I stuck at 198 running pods?
If I described one of the pending pods, I found the following Warning:
Warning FailedScheduling <unknown> default-scheduler 0/100 nodes are available: 100 Insufficient pods.
Well... that's not too fun. I inspected one of the nodes using kubectl get node [node name] -o yaml, and found my problem in the capacity properties:
capacity:
cpu: "2"
memory: 980068Ki
pods: "4"
Apparently (this is something I forget when I'm not running with giant beefy C5 instances) in AWS, individual nodes are limited to running as many Pods as there are available CNI network interfaces per instance, and this number varies widely per instance type.
The t3.micro instances can only run, at maximum, 4 Pods per node!
And indeed, I can verify that only 400 total Pods are running in the cluster (total running pods include the management pods that run on each node for EKS):
$ kubectl get pods --all-namespaces | grep -i running | wc -l
400
Welp. At least aws-labs maintains a list of how many pods can be run per instance type.
It looks like the most cost-effective option would be for me to run 14 m5.16xlarge instances. For one hour, this would cost approximately $45, plus the cost of the EKS cluster control plane.
Alternatively, I could run 173 t3.2xlarge instances, and one hour would cost approximately $60, plus the control plane.
In any case, the vCPU requirements quickly get out of hand—for the m5's, I'd need my vCPU limit increased to at least 896... and I'd already stretched a bit further than my limited AWS testing account overlords allowed—they only gave me 300 vCPUs out of the 400 I requested.
Now, if I had an account that had organically grown over time to consume a ton more compute resources, I could snap my fingers and get it done.
Another alternative is to ditch AWS's VPC CNI networking entirely, and use a different networking plugin for the EKS cluster, but creating an EKS cluster and switching it to another CNI like Weave or Calico is a bit of a chore.
Post-original-blog-post-writing-update: AWS approved my limit increase request for 1000 vCPUs right as I was getting ready to publish this... so I tried building the cluster again—this time with 14 m5.16xlarge instances, and what do you know, it worked! I got the 10,000 pods running, and racked up a little more EC2 charges on my AWS bill, but it was worth it—out of four attempts (spoiler alert!), two were able to get the 10,000 Kubernetes pods into a functional state.
I had to tear down the cluster pretty quickly though, considering it would cost over $31,000/month to keep it running using on-demand billing!
Trying out a K3s cluster
I was going to throw in the towel, but I decided to give K3s a shot. I've been using it for my Raspberry Pi Clustering video series, and it seemed more lightweight. Maybe I could throw together a master and 100 EC2 instances, and get it working that way?
I built a new Ansible playbook that deployed a different set of CloudFormation templates. This time, I built:
- A VPC with one subnet in one Availability Zone, just to keep the networking simple.
- A single c5.2xlarge instance to be used as the K3s master.
- 100 c5.large instances in an Auto Scaling Group to be used as the K3s nodes.
Note: I originally tried using a single t3.micro master, and 100 t3.micro nodes, and they worked—up until around 7000 pods had been deployed. At that point they all started losing their CPU burst capacity, and all the nodes quickly dropped out of the cluster. I couldn't even get logged into them anymore, so I killed that cluster pretty quick.
I ran the playbook, which dutifully booted 101 new EC2 instances, then downloaded the K3s Ansible Playbook from Rancher. I populated the hosts.ini inventory using the IP from the master and list of all the IPs of the nodes, which I grabbed using the AWS CLI:
aws --profile jeffgeerling --region us-east-1 ec2 describe-instances \
--filters "Name=tag:Name,Values=k3s-node" \
"Name=instance-state-name,Values=running" \
--query "Reservations[*].Instances[*].[PublicIpAddress]" \
--output=textI tweaked a couple variables like the ansible_user in the K3s Ansible Playbook's group_vars file to work with the Debian AMI I chose, and then ran the playbook with:
ansible-playbook site.yml -i inventory/hosts.ini
After the playbook ran, I logged into the master instance and confirmed all 100 nodes were Ready:
# kubectl get nodes | grep Ready | tail -n +2 | wc -l
100
With that confirmed, I deployed the 'hello world' app (not using Ansible this time, just for lack of time...):
kubectl create deployment hello-node --image=k8s.gcr.io/echoserver:1.4
Then I edited the deployment (kubectl edit deployment hello-node) and set the replicas to 10000, and waited... and waited and waited some more! I monitored the progress with watch "kubectl get pods | wc -l", and then after that finally reached 10000, I confirmed all the pods were Running:
# kubectl get pods | grep Running | wc -l
10000
Victory!
After all that, I made the video that's linked at the top of this post, tidied up the codebase to put it on GitHub, and finished writing this post.
Conclusion
In the end, I found out that burstable T3 instances aren't ideal for massive amounts of pods, no matter what. I run into networking and burst CPU limits. And EKS has some annoying limitations with it's current VPC CNI networking, but those could be overcome if you take the time to swap out a different networking solution. I got everything working with
All the code I used to build and destroy this cluster is available in a GitHub repository: 10,000 Kubernetes Pods for 10,000 Subscribers. And the video is available on YouTube: 10,000 Kubernetes Pods for 10,000 Subscribers.
You can learn more about Kuberentes automation with Ansible from my book, Ansible for Kubernetes. I'm also creating videos about Ansible, Kubernetes, and Raspberry Pis on my YouTube channel, so subscribe there for updates!
Comments
It seems like what you really needed was 1000 Raspberry Pi's... ;)