The following is a transcript of the content in my AnsibleFest Atlanta 2019 session, There's a role for that! How to evaluate community roles for your playbooks.
Introduction
I'm Jeff Geerling, I wrote a book on Ansible (Ansible for DevOps), I have used Ansible on an almost daily basis for hundreds of different projects since 2013, and I now work with Red Hat's Ansible team as a technical contractor.
Some people wonder ask how teams can be productive while maintaining many applications on a variety of cloud providers. One of the key reasons is reliance on Ansible content contributed and maintained by others.
In this presentation, I'll go through my process for evaluating community content before incorporating it into my automation playbooks. I'll also talk about what risks are involved in including external dependencies and how to mitigate those risks.
Managing Risk in Dependency Hell
Before getting into Ansible, it's important to have a good understanding of software dependency management in general. And any discussion of the sort has to start with a dive into Dependency hell.
When you're going to go skydiving, you have to sign a waiver and accept responsibility for the risk you're about to take. Similarly, if you're about to rely on other people's libraries and software, you should know and accept the risks associated with doing so.
When I mention the term Dependency hell, I mean two things:
- The more traditional hell of managing many possibly interdependent software libraries, with differing version constraints, which can result in uninstallable libraries or libraries which refuse to be updated due to complex versioning issues.
- The hell of having to deal with maintenance and release cadences of upstream software when planning the maintenance of your own.
Who has ever seen a screen like the following when installing software?
The following packages have unmet dependencies:
postgresql-9.3 : Depends: postgresql-client-9.3 but it is not going to be installed
Depends: postgresql-common (>= 142~) but it is not going to be installed
E: Unable to correct problems, you have held broken packages.
You can run into these issues with almost any software package manager, like yum, apt, pip, gem, npm, or composer.
Dependency Hell is also about Trust
Another important component of relying on upstream packages is trust. If you're building infrastructure or setting up networking for an application important to your company's financial success, you better be sure you can trust the upstream maintainers.
It's important to ask the following questions:
- Will the maintainers fix major bugs (e.g. issues which cause users' playbooks to completely break) in a timely fashion?
- Do the maintainers take security seriously?
- Do you trust the upstream maintainers to review PRs and code contributions with the same rigor as you?
- Have the maintainers been around a while, and have a history of maintaining the project well, or did they push some code to GitHub and disappear?
If you can answer these questions with a yes, then you should be able to establish some level of trust with the upstream maintainers.
But if you answer no, be careful depending on packages from those maintainers. It's not always a bad idea (especially if the current version of the package does exactly what you need), but you'll likely be adding to your project's technical debt.
Trust goes both ways, too. If you are evaluating a new role or module, and it doesn't behave like the documentation says it should, or if you find some typo, go ahead and open an issue or file a PR! As an open source maintainer, I exercise more patience if I'm dealing with a user I've observed being helpful before.
NIH vs PIE

Finally, it's good to know thyself—to know what you're comfortable with. There are two typical philosophies when it comes to using dependencies:
- Not Invented Here (NIH): The belief you are better off managing your own code, writing your own libraries, and maintaining everything in-house. At its extreme, NIH can lead to reinventing the wheel and being left behind with proprietary, non-standard software.
- Proudly Invented Elsewhere (PIE): The belief that using existing code and libraries built and maintained by others leads to better applications and easier maintenance. At its extreme, can lead to dependency hell and major rework if essential libraries or packages go unmaintained or don't take your organization's needs into account.
Note: Sometimes the idea of 'Not Invented Here' is described as the 'IKEA Effect', where you place much higher value on things you build yourself, even if they are not as high quality as what you'd get if you got it pre-assembled.
Some organizations pick a side (some by necessity, like NASA's Apollo program, others out of fear or ignorance), but most fall somewhere in the middle. For my own Ansible projects, the ratio of NIH to PIE varies dramatically based on the project goals.
For a one-off project I know will be irrelevant in a year or two, I might exclusively use community roles and just plug them together using variables.
For a project which helps the company's core product line, I'll often have more bespoke code, and only rely on a few roles where I have an extremely high level of trust for the role maintainers.
Ansible Galaxy, today
Ansible Galaxy started back in 2014 as the "hub for finding, reusing, and sharing the best Ansible content."
Galaxy has mostly remained the same, with incremental improvements every year. This year has seen the most significant changes to Galaxy, with the addition of collections, but on the whole, Galaxy is still the hub for the best Ansible content.
Aside: Automation Hub is another new hub for Ansible content, available to Red Hat subscribers, but as it's not open to all Ansible users I won't specifically be covering it in this presentation. The main difference between Galaxy and AH is that AH will have 'certified' content, whereas Galaxy will continue to have all the other community content that is not supported by Red Hat.
I figured the best way to teach you how to evaluate Ansible roles from Ansible Galaxy is to show you my process, using two different examples.
How I choose a role from Ansible Galaxy
Every time I consider using a role from Ansible Galaxy, I ask four questions:
- What do I need?
- How do I find it?
- How do I narrow down search results?
- How do I select the role I am going to use?
Real world example: Zabbix
Let's run through a real-world example. I was just told by my networking team they want to have a Zabbix server configured for them. I haven't really worked with Zabbix before, but I know it's a popular monitoring platform that runs on Linux, with packages for Red Hat, Ubuntu, and most other popular Linux distros.
Manually installing Zabbix
Usually if I don't know the software well, I'll spend a few minutes just getting familiar with it's install routine, and how to manage basic configuration and setup. Before I can evaulate other people's automation code, I need to have at least a basic understanding of what is being automated!
In Zabbix's case, I spin up a Docker container running CentOS, and play around, following Zabbix's install guide.
I start a Docker container and enter it:
$ docker run -d --privileged --name zabbix -p 8080:80 geerlingguy/docker-centos7-ansible /usr/lib/systemd/systemd
$ docker exec -it zabbix /bin/bash
Then I install Zabbix and start MariaDB:
# rpm -Uvh https://repo.zabbix.com/zabbix/4.2/rhel/7/x86_64/zabbix-release-4.2-2.el7.noarch.rpm
# yum clean all
# yum -y install zabbix-server-mysql zabbix-web-mysql zabbix-agent mariadb-server nano
# systemctl start mariadb
After installing Zabbix and MariaDB, I create a database:
# mysql -u root
MariaDB> create database zabbix character set utf8 collate utf8_bin;
MariaDB> grant all privileges on zabbix.* to zabbix@localhost identified by 'zabbix';
MariaDB> quit;
Then I populate the database. Installing Zabbix from an RPM inside a Docker image causes some files to go missing, including the schema creation script referenced in Zabbix's documentation. So I download the 4.2.6 release file and import the individual schema files:
# mysql -uzabbix -pzabbix zabbix < schema.sql
# mysql -uzabbix -pzabbix zabbix < images.sql
# mysql -uzabbix -pzabbix zabbix < data.sql
Finally, I configure Zabbix and start it:
# nano /etc/zabbix/zabbix_server.conf (to edit the DBPassword=)
# nano /etc/httpd/conf.d/zabbix.conf (to edit php_value date.timezone)
# systemctl restart zabbix-server zabbix-agent httpd
Now I can visit http://localhost:8080/zabbix, and follow the frontend installation wizard. I'll be monitoring systems in no time!
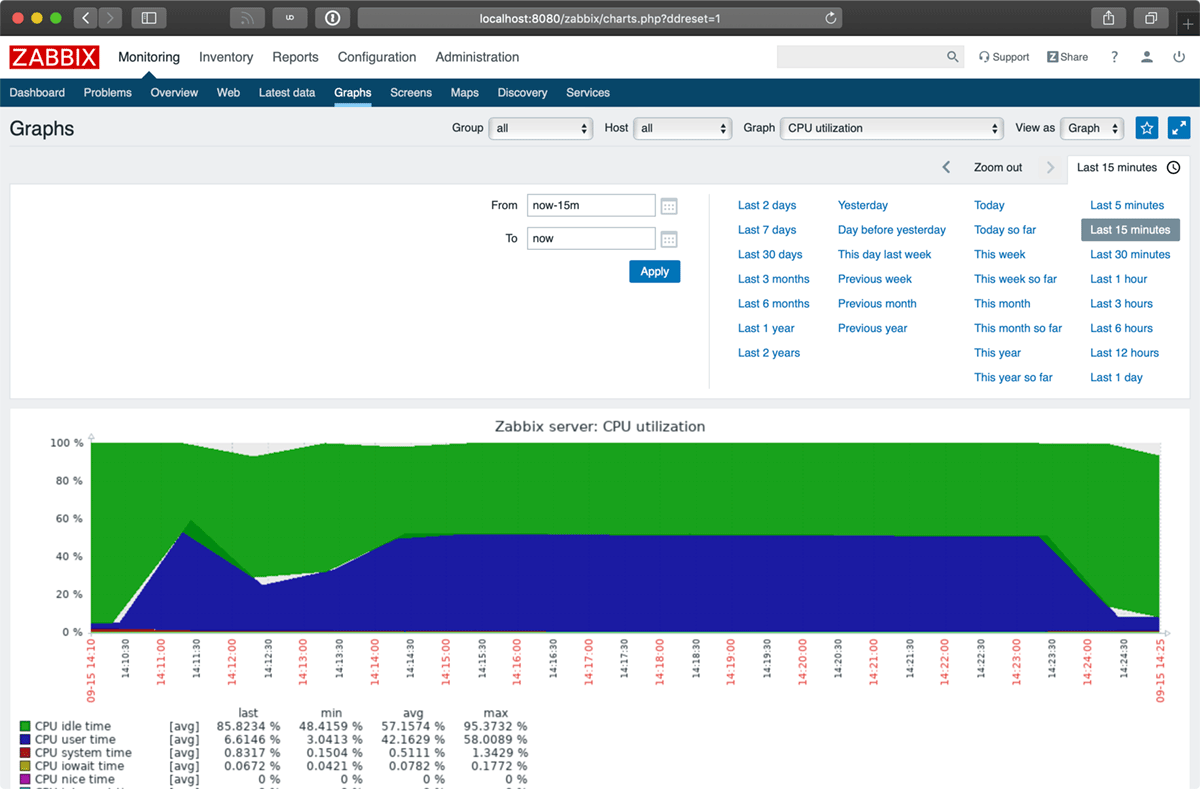
Choosing a Galaxy Role for Zabbix
Now that I'm familiar with Zabbix's installation process and basic configuration, I am confident enough to look through Galaxy to find a role that suits my needs.
First, I'll search for 'Zabbix' in Galaxy:
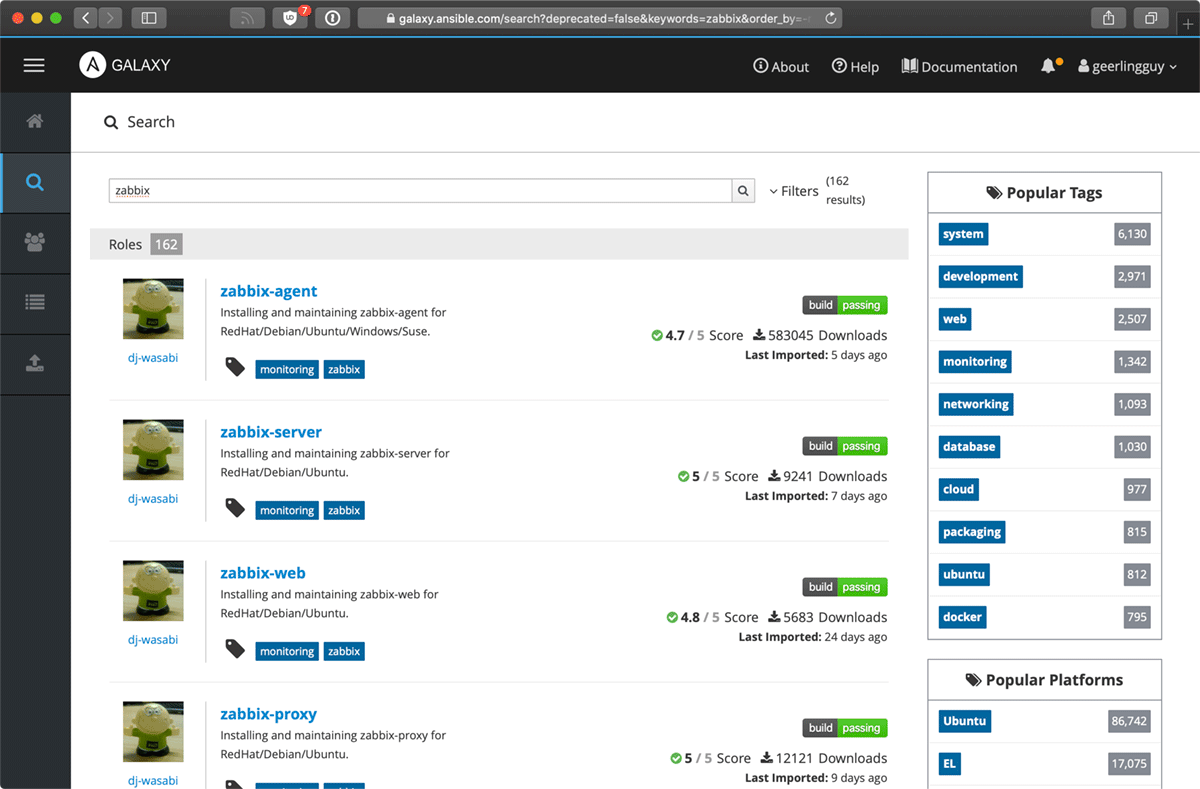
Now I look through at least a couple pages of results. At a glance, I can already see a few helpful metrics to the right of each role to help sort the wheat from the chaff:
- If the role uses Travis CI for automated tests, I see a 'build' graphic showing passing or failing tests.
- There is a Galaxy score for the role based on the code quality and community ratings (if any).
- There is a download count, showing how many times the role has been downloaded from Galaxy.
- There's a 'last imported' date, showing how recently the role has been updated.
Individually, these metrics are not very helpful. But taken together, I will give more consideration to a role that has any form of automated tests, has at least a 4 or 4.5 rating, has more than 100 or so downloads, and has been updated in the past year or so. With rare exception, there's almost always a role or two matching these criteria.
As I find a few roles from different authors or namespaces that look promising, I open them in new tabs. Then I look through the details of the role:
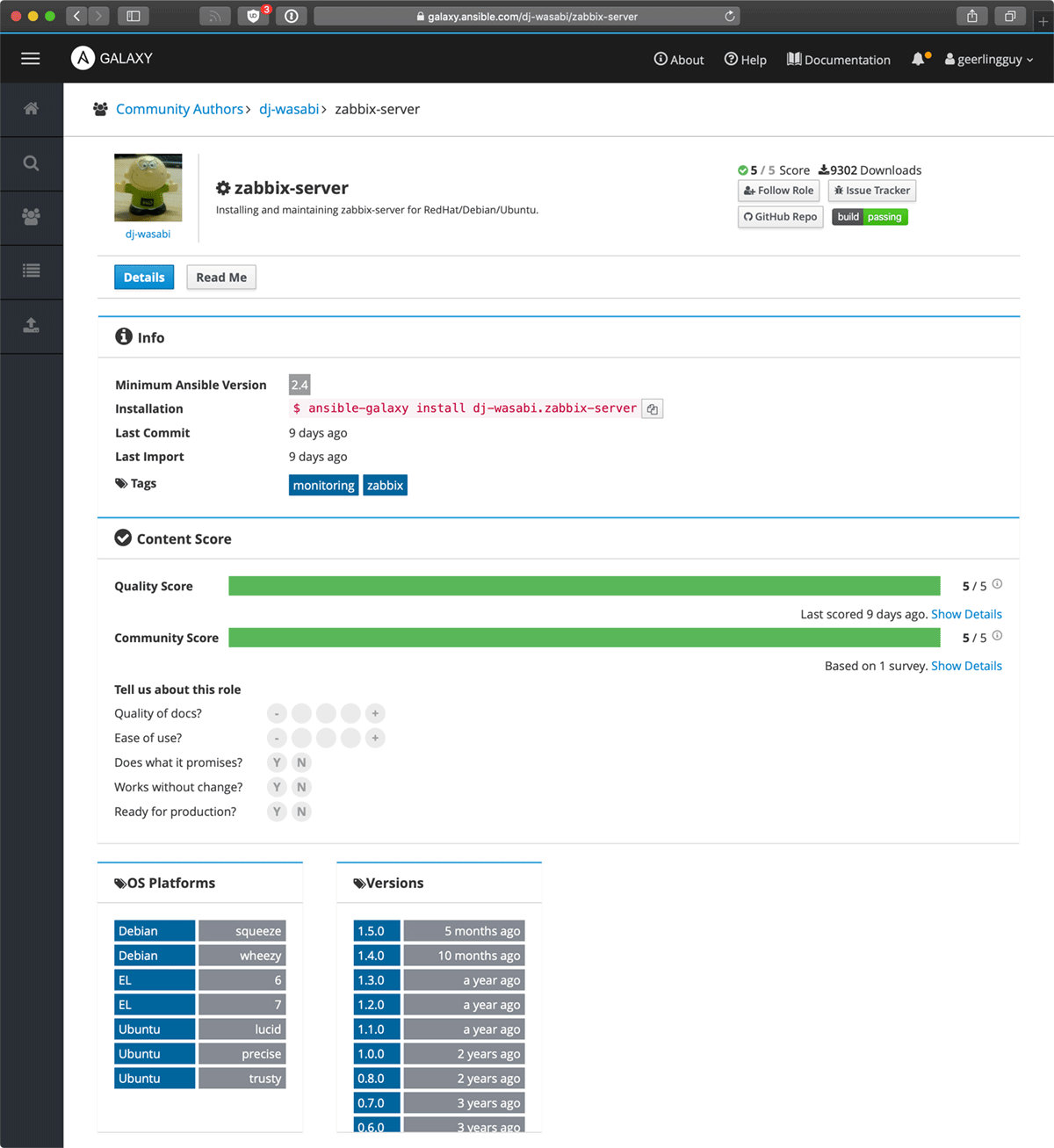
- I'll first click on the 'Read Me' tab, and skim through the role's basic documentation.
- Then I'll go back to the Details tab, and if either the quality or community score is less than 5, I'll look at the details and see if it's mostly nitpicky things or noise, or if there could be serious issues.
- Next I look at the OS Platforms; this is a little philosophical, but I like to see a role support at least two OSes (even if in the same family, like Ubuntu and Debian, or Fedora and Red Hat), because it at least means the author is likely abstracting certain operations (like package management) which makes it easier to maintain long-term.
- Obviously, I also make sure the role supports the OS I'm targeting!
- Finally, I look at the Version history. If the role is very new this can be ignored, but for roles that have been out for more than six months, the version history should show some sort of release cadence. For software that's been around a while (like Zabbix), there probably shouldn't be dozens of releases in the past year... just a few, to keep up with long-term changes and new Ansible versions.
Now that I've narrowed it down to two or three roles, it's time to jump into the roles' code. Some people skip this part, and trust the role does what it says. Usually this is the case, but sometimes it is not (as I'll highlight soon).
For each of the finalists, I'll download the role and browse through it locally (or in GitHub's UI):
ansible-galaxy install -p ~/Downloads dj-wasabi.zabbix-server
I'm looking for the following:
- Code is well-formatted, with proper spacing and no egregious issues.
- Files like task includes are logically organized and have meaningful names, making it easy to read through the flow of the role.
- Variable files in
defaultsorvarshave meaningful variable names. - The repository has an open source license (should be specified in the
meta/main.ymlfile at least). - The repository has a comprehensive README or some other accessible documentation.
- The repository contains some amount of tests, ideally using Molecule or other standardized tooling.
Once I've skimmed through the code, I'll also make sure it's doing all the steps I remember from my manual installation, at a high level:
- Install Zabbix
- Create and populate a database
- Configure Zabbix
- Start Zabbix
Finally, I'll either use a local docker container or VirtualBox VM and a simple playbook to run the role with its defaults and see what happens. Ideally, everything 'just works', and I end up with a running Zabbix installation!
Avoiding Bad Judgement
I said earlier a code review is necessary because roles don't always do what you'd expect based on documentation. So I'd like to run through my same process on a special role I built just for this presentation: Bad Judgement.
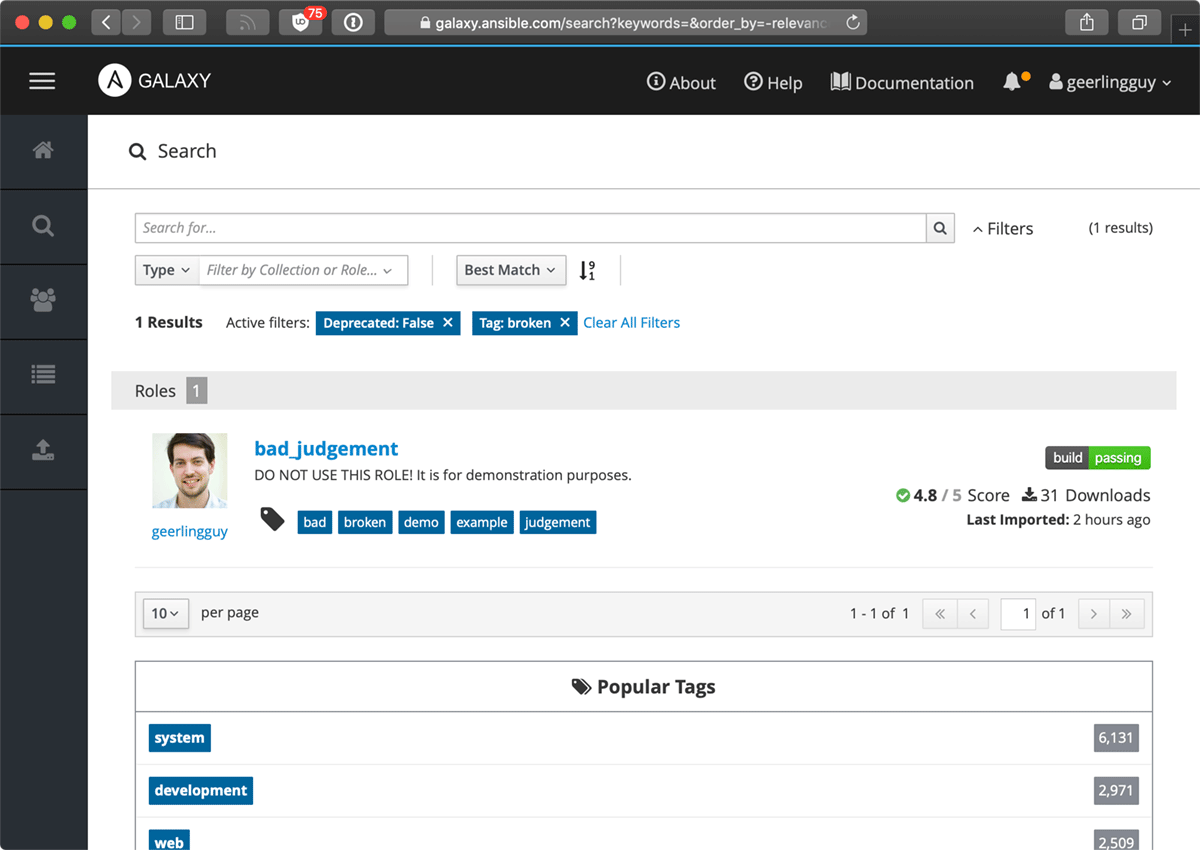
In the search results, I can see this role has:
- A passing test build
- A quality and community score of 4.8 out of 5
- Was imported recently
- 31 Downloads
So, the download count is a little low, but this is a specialty role, and I seem to see this geerling guy a lot elsewhere on Galaxy, so maybe I should trust the role at face value. There is a strange warning about not using the role, but I think I'll ignore that for now. Nobody reads descriptions anyways.
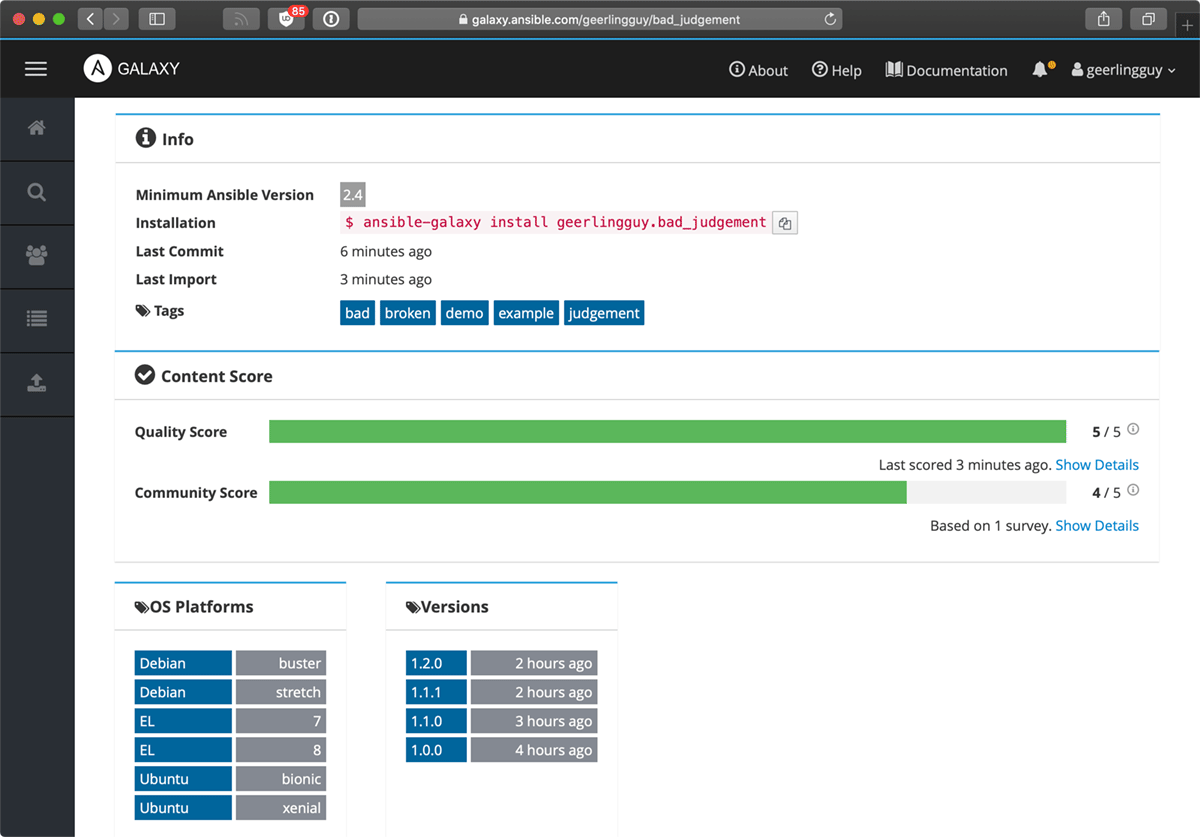
On the details page, it looks like things are pretty good. There's a nice assortment of supported platforms, and since I'm going to use Debian for this project, I'm happy to see it's supported. There isn't much of a version history, but there are some recent versions, and it seems like the role is actively maintained.
So if I give up at this point and decide to start using the role, it might actually work. I'll glance at the README, set a few defaults, and include the role in my project's requirements.yml, thinking nothing more.
But it's important to evaluate the code in the role. This example role goes to the extreme, but each one of the flaws I'm about to reveal is based on something I've seen in real-world roles I've evaluated!
Code Reviewing the Bad Judgement role
There are comments revealing many of the mistakes in this role's tasks, but I'll highlight a few things I'd find most concerning in a code review:
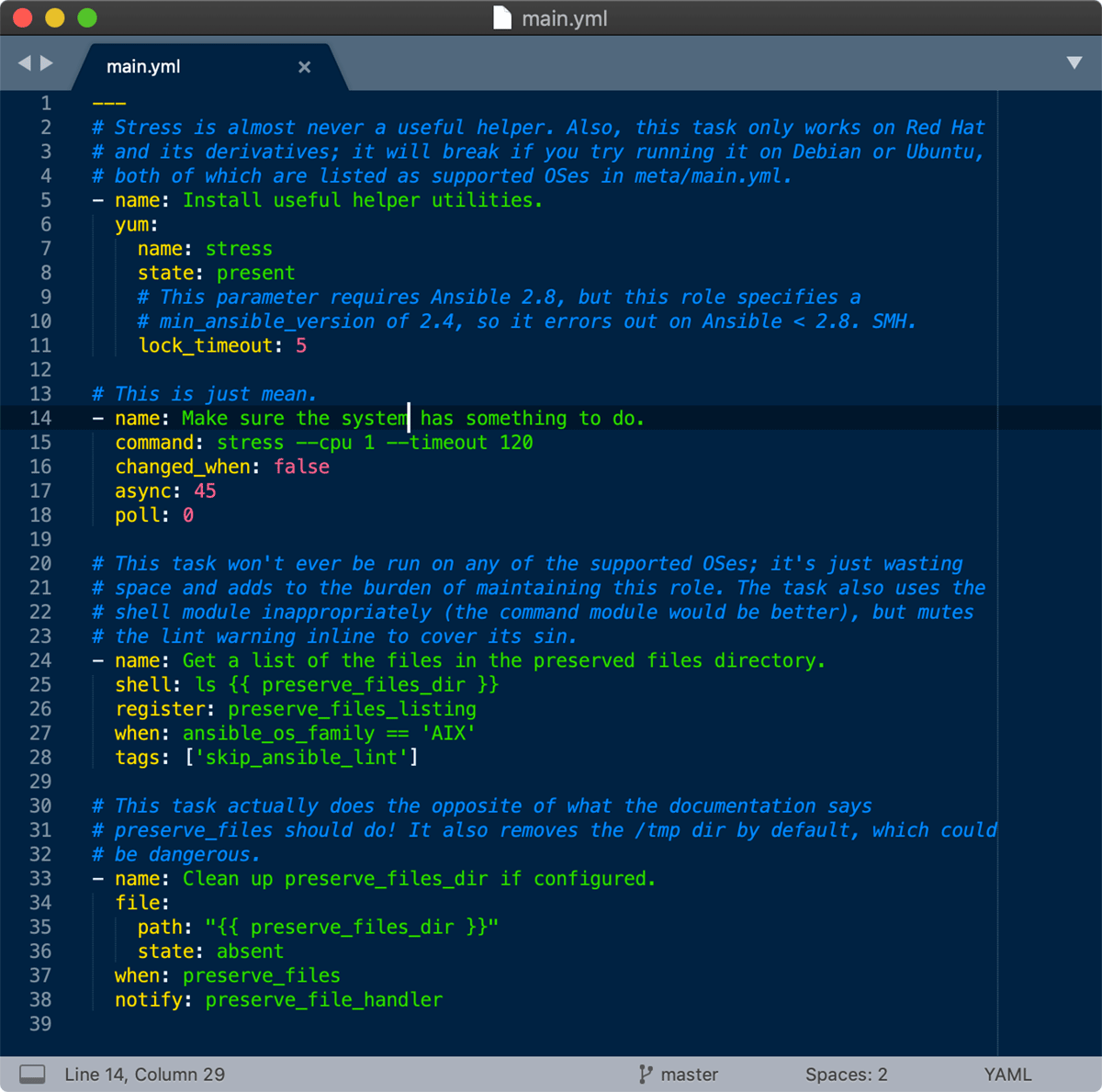
The first task uses the yum module, but does not have a when condition to restrict it to running on systems (e.g. Fedora, Red Hat, CentOS) where yum or dnf are present. On top of that, it uses a yum module parameter (lock_timeout) which requires Ansible 2.8, even though the role itself states a minimum requirement of Ansible 2.4.
The second task accomplishes nothing, besides increasing the speed at which the server's fans run for two minutes. There's no reason to run this task, and it was likely committed when someone was testing something, but never removed. This is a pretty innocuous flaw (it will just burn some CPU cycles for a couple minutes), but I've seen test code do much more harm when it leaked into a production system.
I'm immediately suspect of the third task because it has the skip_ansible_lint tag. This means ansible-lint finds a flaw in the task, and now I have to figure out what it is. And further, unlike the first task, this task does have a when condition to restrict it to a single OS family—AIX. Unfortunately, AIX is not listed as a supported OS, so ¯\_(ツ)_/¯.
The final task has a when condition that does the opposite of what the preserve_files documentation in the README says; it should preserve files when preserve_files is true, but in this case it's actually deleting them when it's true!
The last task also notifies a preserve_file_handler, so let's take a look at that:
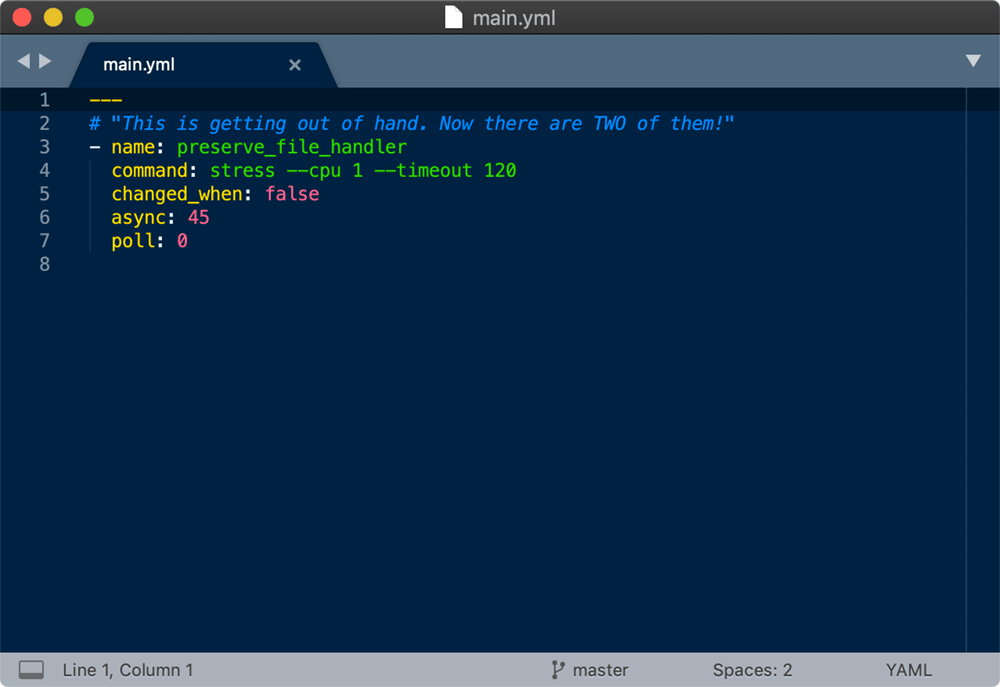
You've got to be kidding! Now two of my processors may be tied up for two minutes after I run this role. What was the role maintainer thinking!?
This role is pretty egregious, and it's easy to spot its flaws. But in practice, many roles will be much better—or worse. Some things role maintainers can do to make this review process easier:
- Keep task files short (< 100 lines). Use includes to group tasks together. (Make it easier to do code review.)
- Keep roles simple; do one thing, do it well. Make your role work easily with other roles.
- Keep tabs on your role's Ansible Galaxy community score and content grade.
- Add example playbooks to show your users how to use your content. Bonus points if you have test playbooks (e.g.
moleculeoransible-test) which are used for CI.
As a final test, I usually put a role through its paces before running it on a production server. I set up a local test environment, get everything working well there, and then commit my Ansible playbook / project to an SCM repository which I'll use to deploy to a live server, either via Tower or some other central deployment system.
Ansible Galaxy, now with Collections
This year's headline Ansible feature is Collections. What does that mean for those of us used to maintaining or consuming roles from Ansible Galaxy? Unfortunately, that is not clear yet. Collections have been in tech preview since Ansible 2.8 was released, and I've been exploring them quite a bit.
There are a number of difficulties for the Ansible content consumer which need to be addressed in the coming year, as more and more collections will be published (and, possibly, fewer roles?):
- Now that plugins and modules are included in a collection (along with roles), without affecting the 'Quality score' displayed on Galaxy, what other code quality criteria can we use to quickly sift through collections?
- What happens if a collection doesn't have a license that allows forking (e.g. a more restrictive license than something like MIT, BSD, GPL, or Apache)?
- What happens when collections don't have a public source repository and build process? How do we trust the collection code has not been tampered with if we can't reproduce the collection build artifact?
These questions and more are what I've been pondering for a few months, and I think as a community we'll have to come together and find new best practices. Maybe I'll give this presentation again next year summarizing our collective learnings!
One thing that will not change, however, is the fact that you should not just trust a collection at its face value. Just as we can see with Ansible Galaxy roles, contributed content can vary wildly in quality and maintenance status. You should use all the tools you can to evaluate if content is right for your Ansible automation project.
Conclusion
Ansible Galaxy is a gold mine of great Ansible content. But just like a real gold mine, it takes some effort to find the gold in the midst of the barren rock. The tools shown in this presentation will make your role prospecting successful, and hopefully convince you to get off the Not-Invented-Here island and manage dependencies better!
Comments
Very nice read, it is good to see you pointing out the issues with copying /pasting code or Ansible roles from the Internet without first understanding what it is doing. i think new users could benefit a lot from this post becuase
1) it is a good way to learn and look at other peoples solutions. gives you a different viewpoint on a problem you might be having.
2) prevents you damaging a production environment
it today's programming it is second nature to quickly google for an answer and copy the first thing you see without judging the implications.