tl;dr: EFS is NFS. Networked file systems have inherent tradeoffs over local filesystem access—EFS doesn't change that. Don't expect the moon, benchmark and monitor it, and you'll do fine.
On a recent project, I needed to have a shared network file system that was available to all servers, and able to scale horizontally to anywhere between 1 and 100 servers. It needed low-latency file access, and also needed to be able to handle small file writes and file locks synchronously with as little latency as possible.
Amazon EFS, which uses NFS v4.1, checks all of those checkboxes (at least, to a certain extent), and if you're already building infrastructure inside AWS, EFS is a very cost-effective way to manage a scalable NFS filesystem. I'm not going to go too much into the technical details of EFS or NFS v4.1, but I would like to highlight some of the painful lessons my team has learned implementing EFS for a fairly hefty CMS-based project.
Monitor EFS Burst Credits
I'm pretty sure this is one of the most mentioned suggestions in every guide to using EFS I've seen. And it's par for the course with AWS offerings—you can usually start out using the free/cheap tier of a service, but once you start putting production loads on the service, you'll have your first major outage with no discernible cause.
That is, if you're not monitoring burst credits.
My team spent over an hour trying to diagnose why MySQL connections were stacking up, application threads were clogged, and extremely few requests were getting responses. Finally, we noticed that file operations were really slow. Really really slow. And then I remembered I had built a dashboard in our monitoring system for EFS, so I looked there, found that our Burst Credits were expired, and our Permitted Throughput went from 50 Mbps to 0.5 Mbps. And this was in the middle of a full EFS backup (more on that later!).
So, make sure you add alerts in CloudWatch or elsewhere on your BurstCreditBalance. If it starts going down, make sure it doesn't keep going down. And if you need more burst credits, or a higher normal throughput limit, see the next section:
Write dummy data to get better performance
NOTE: As of July 2018, EFS now supports Provisioned Throughput. For many people, this is a better way to guarantee a certain level of performance instead of writing large files to your EFS filesystem.
For most AWS services (well, at least all the ones predicated on instances and/or clusters), you can always upsize your instances, or change from network-optimized to CPU-optimized, or RAM-optimized, or GPU-optimized.
For EFS, there is no 'instance class'. The only real control you have over what kind of I/O limits you have is switching between 'general performance' (good for low latency, high horizontal scalability), or 'max IO' (good for larger volumes of data transfer, but with slightly higher latency).
When you create a new EFS volume, you get a paltry .5 MB/s sustained transfer rate, and 7.2 minutes worth of burst credits (up to 100 MB/s). How do you increase these limits? You write a giant file to the filesystem, and EFS takes up to an hour to increase your limits, according to this chart (taken from the EFS Performance page):
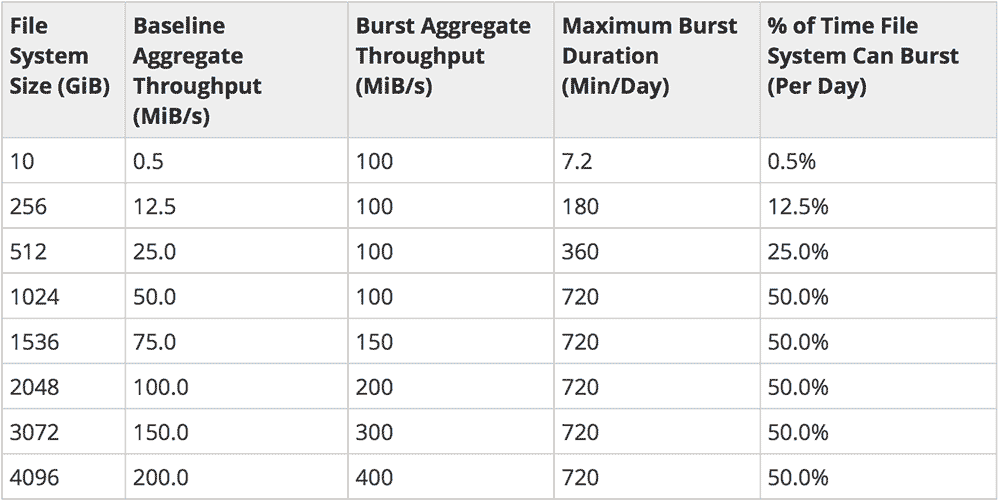
Lesson learned: Immediately after creating a new EFS volume, mount it somewhere, and write a large file to it (or many smaller files if you want to delete some of this 'dummy data' as your data usage expands):
sudo dd if=/dev/urandom of=test_large_file bs=1024k count=256000 status=progressBe sure to exclude such files from any backups you take, otherwise you'll be paying for more backup space, as well as all that extra transfer bandwidth to back up the large file that gives you the bandwidth in the first place! I've asked AWS about any chance to create volumes and not have to write big files to jump to higher IO stats (after all, you don't start on a t2.micro instance when you sign up for a beefy c5.4xlarge in EC2!). If you want to pay up front for the performance, it seems odd that AWS won't allow it. I know many people who have been burned by this same problem.
Don't even think about running app code from EFS
I see a lot of people try to use EFS (or NFS in general) as a jerry-rigged deployment mechanism so they can manage a codebase in one directory shared on multiple servers. NFS/EFS, Gluster, ObjectiveFS... all these networked filesystems are not built for low-latency, multi-file access. If you're running a PHP or Ruby application with hundreds or thousands of small files that need to be read from disk (even if using opcache), you're going to have a very bad time. Same goes for using Git on EFS/NFS—almost always a bad idea.
Instead, use a tool like Ansible to deploy your code to a local filesystem on each server (hey, I wrote a book on that!); or build a 12-factor app and use disposable servers or containers to deploy your application code. Whatever the case, run code from a local, fast filesystem. Even a slow spinning-disk local filesystem will be a lot faster than a file system accessed over the network (see Latency Numbers Every Programmer Should Know).
Use NFS/EFS for storage of things like media assets, exported data files, and asynchronous logs that don't require extremely low-latency to work well. You don't ever want EFS to be in the critical path of your application's code.
Use multiple EFS volumes for latency-sensitive directories
If you do have to have a shared volume store latency-sensitive components of your application (e.g. lock files used by flock), and there is other data (e.g. media files or logs) being read from and written to your EFS volume, consider adding a second EFS volume used only for the latency-sensitive operations. This still won't make things fly like using the local disk, but you'll have more consistent latency at least. (Note that I'm currently doing some testing in this area—I'll update this post if I find any other helpful improvements for this use case.)
Use the correct mount options
AWS recommends the use of certain NFS mount options when setting up EFS mounts in Linux. Unless you have very specific needs, and have tested and thoroughly benchmarked any other options or changes to the recommended options, use AWS' recommendations.
They likely tweak their NFS backends and networks for the specific rsize and wsize they specify.
Also, use NFS v4.1 if at all possible. It might be difficult to get an NFS 4.1 client installed on some older OSes, and in that case you can consider sticking with something older—but if not, use the latest and greatest; there are a lot of protocol improvements.
Careful with backups
EFS backups are one of the most annoying pain points of using EFS. For many AWS products, like Aurora, there is a dead-simple, easy-to-configure, and inexpensive snapshot process that allows easy backup and restore. With EFS... you're pretty much on your own.
And if you're like me, and you design a backup process that basically copies all X GB of files on EFS to a new server each backup—and you don't rate-limit the server's file copy—then you realize your backup just depleted your EFS burst credits, and now production is offline while EFS scrapes along at 0.5 MB/s ?.
Summary
I've used Gluster, NFS, EFS, and a few other shared filesystems for various projects. All have their tradeoffs, and all will, by the nature of being accessed over a network interface, be at least an order of magnitude slower than accessing files on a local (or in AWS, EBS) volume. The best thing to do when needing horizontal scalability is write your applications to not be dependent on low-ms-level file operation latency, and move things like lock mechanisms to a different layer, e.g. Redis or database.
Comments
Thanks Jeff for a well written piece, which summarised pretty much all of the fun we had setting up EFS last year.
The only thing I'd differ about is the ability for EFS to handle PHP. The trick with getting opcode caching to play nicely with EFS is opcache.validate_timestamps = 0, and ensuring that your other opcache settings allow your entire codebase to fit in RAM (memory_consumption, max_accelerated_files etc). It did take us a while to tune this the right way for our rather large monolithic legacy application, but the end result is instances that scale up and are ready to serve in just over 30 seconds, as opposed to the time it used to take us to rsync EBS to EBS (usually a couple of minutes). Our usage patterns for this particular application are incredibly spikey, so this made all the difference in the world to us.
Having said that, we're going the 12-factor, pre-baked container route for our new applications - it's much easier to go this route on greenfields projects and (should) pay dividend longer term.
I know this is an EFS article, but did you ever do any Gluster performance-testing where:
I have used Gluster in the past, but only on some local 1 Gbps networks, never inside AWS. I know many people who do use it in AWS, though, and I know that there are some tradeoffs (as with any networked filesystem):
Wrote a CFn node-fleet template that makes initialization of an arbitrary number of nodes trivial. Doesn't really do anything for the ease of node-replacement after a failure, though. Need to add in stuff like CloudWatch alerrts and Lamba and/or SSM and just haven't had the time to do it (so, included a "here's how you do it, manually) README in the associated git project.
I was mostly curious what your experience had been with respect to benchmarking, especially since the fifth-generation instance-types have become available (e.g., the t3.* instance types start at 5Gbps and don't have the same kind of networking limitations that the t2s did).
Well written article Jeff. One more way to increase burst credit is change throughput mode to 'provisioned'. It can be switched back to busting but you need to wait for at least 24 hours. By that time burst credit will have increased to TB.
One issue I'm facing regarding copy of small files using EFS Sync agent, despite good number of burst credit at least two times it file sync fails with End of File reached. Please let me know if you have solution for this problem.
I have big problems with EFS. I put all php code in EFS but this dont function, cpu consume lot and not controled moments down service because EFS dont response or overbusted. Now i will migrate php code to ebs again and use EFS only to any folders using ln -s
EFS is a good solution, but much limited and we dont have control.
Can you give a brief overview of why EFS is so bad for small file read\writes for something like gitlab or a webserver? I understand for this that block storage will be faster but I dont properly understand the reasoning. Is it to do with the way the files are stored or is it due to the network latency and high availability replication of EFS?
It's the network latency and protocol inefficiency of NFS (vs local block storage). Though on a platform like AWS, slower spinning-disc EBS volumes can also exhibit similar latency. But if you're used to the speed of a read/write-heavy application (like a database) running on a workstation with an NVMe or even SATA SSD, and you run it using EFS or NFS instead, it's going to be excruciatingly slow, probably one or two orders of magnitude slower.
I'm interested to know what "slow" and "fast" file access means.
I'm in the process of replacing a live service with a precomputed data set. The problem being how to store and serve the precomputed data in a perfoment way.
Obviously storing and serving on EFS will be massively slower than local file system, or even EBS but for my purposes single digit milliseconds to read a 120kb file (or to read a few hundred 150 byte files) is perfectly acceptable.
Is that the kind of speed EFS would deliver or are we talking about >10ms to read a small file?