
Sometimes life has a funny way of lining up opportunities, and one presented itself when Patrick from ServeTheHome reached out and said, "Jeff, I have an Ampere Altra Max server. You wanna come see it?"
Of course I did.
But seeing as Patrick is more than 800 miles away, I had to come up with a reason to go see it, so I pulled out my 6-node Raspberry Pi cluster—with it's 24 ARM Cortex A72 CPU cores—and decided to have a little competition.
And of course that competition is documented in a YouTube video:
In the video, Patrick and I talk at length about areas where ARM is strong in the enterprise vs. areas Intel and AMD are still dominant. As a high level summary:
- ARM is great in integer performance and for workloads like running webservers and VMs.
- x86 is great in floating point performance and compute density, especially with the latest generation of AMD EPYC CPUs ('Genoa'—and Intel's Sapphire Rapids Xeon processors are coming soon!).
- The ARM ecosystem has matured to the point where it's enterprise-ready, though it's not without its warts, and while SystemReady is a step in the right direction, the x86 ecosystem has benefitted from many years of relative stability.
- There are now robust and flexible ARM hardware options from a range of hardware manufacturers like Gigabyte, Asa, and Supermicro—including a beast of a GPU-centric machine ServeTheHome will review soon!
But in this blog post, I wanted to focus on the benchmarking we did, and how different ARM systems—including Apple's M1—stack up in terms of historical top500 rankings and performance efficiency.
Benchmarking ARM CPUs
The go-to cross-platform benchmark these days seems to be Geekbench 5, mostly for these reasons:
- It's easy to run
- It runs on (almost) every platform
- It gives a simple single core + multicore score
And it's not a terrible way to get a quick idea of a CPU's potential. But my main complaint—understanding it's a simple benchmark not tied closely to real-world application benchmarks—is that it really only tests bursty performance.

The other major flaw—at least for my cluster benchmarking—is that it's single-node-only. It's not that useful when you want to test a full cluster's compute performance.
And so I lean on Linpack. HPL is not without fault, but one thing it does very well is capture a broader spectrum of CPU performance, especially under extended load, and especially in clustered environments via MPI.
Many systems fall apart if you torture them, pegging all cores to 100% for 30+ minutes.
Plus... it's kinda fun for the sysadmin inside of me to see how my build stacks up historically against the top500 supercomputers.
But I had a problem: HPL is hard to get running across multiple architectures and types of systems. Trying to get it running on niche setups (like Raspberry Pi clusters) leads you down a rabbit hole of outdated blog posts and tricky hacks.
So after working on automating the HPL runs for the past couple years, I finally set up a new project, top500-benchmark, which currently targets Ubuntu and Debian, and runs on either a single node or a cluster.
I've tested it with my Pi cluster, with my AMD Ryzen 5 5600x desktop, with Patrick's Supermicro Ampere Altra Max system, and even with my M1 Max Mac Mini (via Docker)!
The playbook compiles MPI, attempts to set the system's CPU scaling governor into 'performance' mode (otherwise the results can be a bit unstable), compiles ATLAS, then compiles and runs HPL using a tunable HPL.dat file.
For help running the setup on your own server or cluster, see the project README. There may be a few bugs still, as I've only tested across 6 different systems (2 clusters and 4 workstations/servers), but feel free to open an issue if you encounter any problems!
Results
The Pis are slow, but relatively efficient, beating out my Ryzen 5 5600x system—admittedly in a build not well optimized for efficiency.
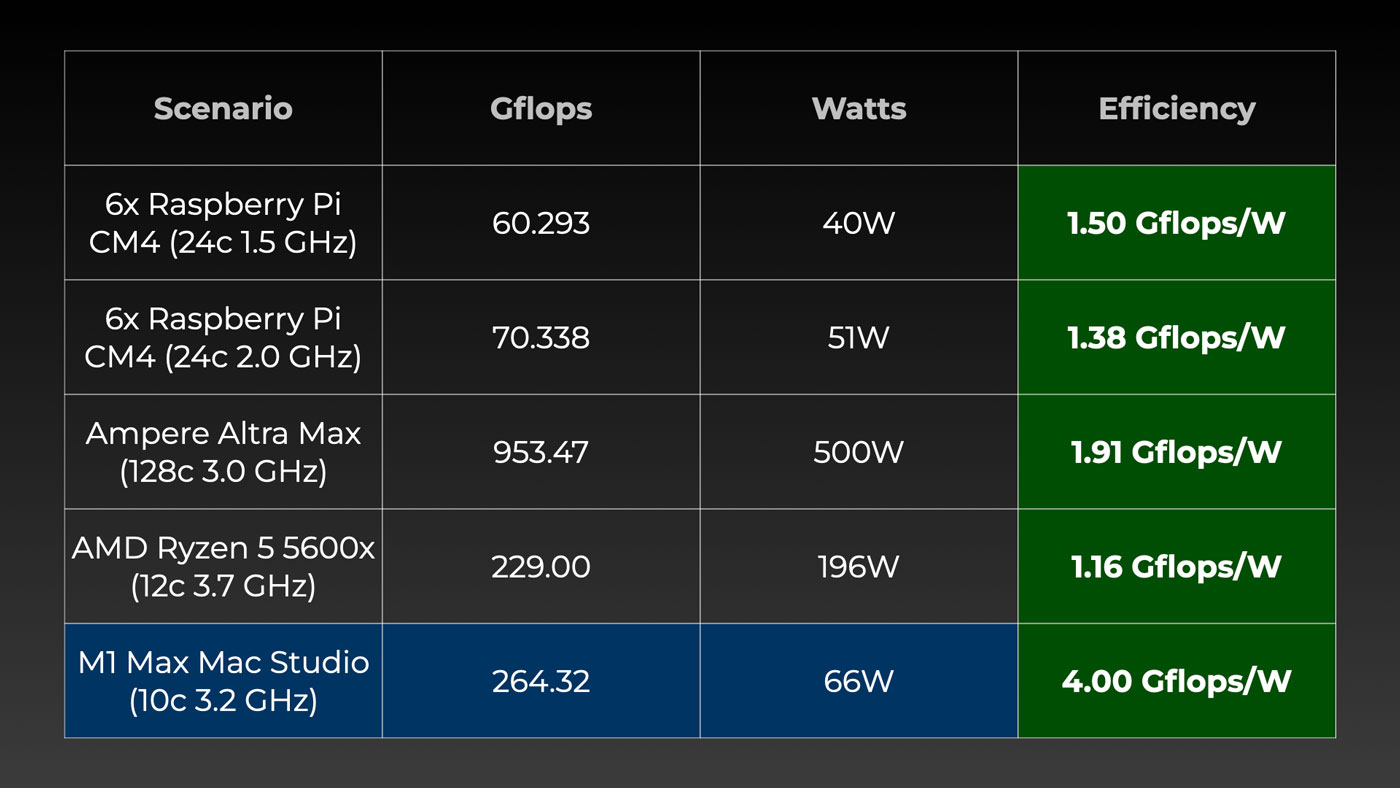
The Ampere system blows past the Pi cluster and AMD desktop, but isn't even half as efficient as the silent little M1 Max Mac Studio on which I'm writing this post!
But efficiency isn't everything—for every use case, you have to consider things like noise, performance and power requirements, software compatibility, etc.
And we're not comparing everything on an even playing field, either. There's infinitely more expansion in the Supermicro server than my M1 Max Mac Studio, and the Ryzen setup I tested was built for gaming and AI testing, not for silence or power efficiency.
Conclusion
Like I said at the beginning of this post, sometimes life throws interesting opportunities your way. In my case I was lucky enough to spend a little time with the Ampere Altra Max. Now I have a point of reference for 'the fastest ARM CPU that can be bought today.' That's a helpful point of reference as I spend most of my days twiddling with tiny ARM systems that are less than 1/100th as powerful!
This opportunity was also the final push towards abstracting my cluster HPL benchmarking tool into its own project. Hopefully more people can experience the ear-piercing whine of server fans as their own servers and clusters plod along trying to place atop the Ampere Altra Max.
Comments
Just wait for M2 Extreme Pro Max Ultra...
I’m a apple kid and know everything about apple and the are known for not really changing there design so
Ampere
hi can u share the hashcat benchmark please