It wouldn't surprise me if you've never heard of Mcrouter. Described by Facebook as "a memcached protocol router for scaling memcached deployments", it's not the kind of software that everyone needs.
There are many scenarios where a key-value cache is necessary, and in probably 90% of them, running a single Redis or Memcached instance would adequately serve the application's needs. There are more exotic use cases, though, where you need better horizontal scaling and consistency.
There are a number of options when scaling Redis, involving read replicas, persistence, etc. But for Memcached, which is inherently simpler (though still a very adequate K-V store), the core focus is less on the wide feature set that makes scalability easier. Services like AWS's ElastiCache for Memcached contain some helpful tooling to make it easier when scaling horizontally (to a point), but without Mcrouter, you usually have to add more caching logic to your application and its configuration than you'd like.
Mcrouter hides an entire cluster (or just one node) of Memcached servers behind one Memcached-protocol-compliant interface, so your application connects to a single instance. All the cluster management happens inside Mcrouter instead of your application.
I won't get much deeper into Mcrouter itself in this post, because the main point is to show how the Operator SDK with Ansible made it easy for me to deploy a scalable self-healing Memcached cluster using Mcrouter into Kubernetes environments.
What is Mcrouter Operator?
![]()
Mcrouter Operator follows the Kubernetes Operator pattern to allow you to manage Mcrouter clusters inside your Kubernetes cluster using Custom Resources (CRs), through a special Mcrouter Custom Resource Definition (CRD).
So instead of setting up a Mcrouter Deployment, a Mcrouter Service, a Memcached StatefulSet, a Memcached Service, and connecting Mcrouter to Memcached manually, you can add a cluster by creating the following resource:
---
apiVersion: mcrouter.example.com/v1alpha3
kind: Mcrouter
metadata:
name: mcrouter
spec:
memcached_pool_size: 5
pool_setup: replicatedWhen you create this resource, the operator sees it and makes all the necessary changes to give you a Mcrouter cluster using a replicated pool, with 5 Memcached pods running.
Here's a graphical overview of how the operator works in tandem with Kubernetes:
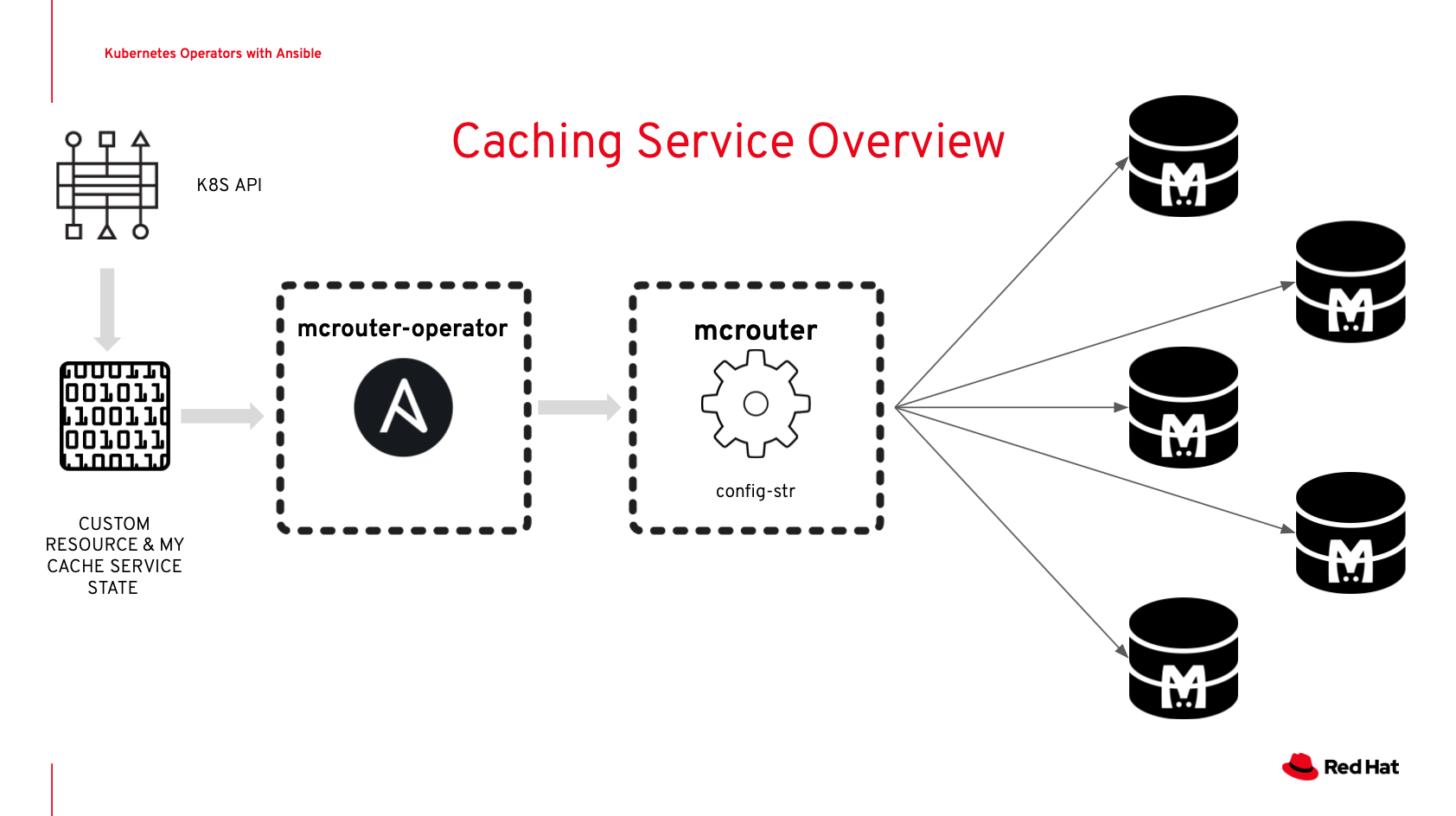
Thanks to [Timothy Appnel](https://twitter.com/appnelgroup) for building this graphic!
The Mcrouter Operator defines a Custom Resource Definition (CRD) for Kubernetes. When a Custom Resource (CR) with type 'Mcrouter' is created, Kubernetes tells the Mcrouter Operator about it, and the Mcrouter Operator then performs a series of actions to ensure the Mcrouter resource exists exactly as described by the Custom Resource.
The Operator also ensures the state remains consistent, and watches for any future changes to the CR. Operators can do a lot more than that, like manage resources outside the cluster, manage backups, or clean up after a CR is deleted.
There is a Katacoda exercise which guides you through much of the content of this blog post interactively; check it out! Ansible Operator and the Operator SDK
Installing and Using Mcrouter Operator
From the Usage directions in the operator's README, installation is very easy. In any existing Kubernetes cluster (e.g. minikube start if you have Minikube and want to test it locally), apply the operator manifest:
kubectl apply -f https://raw.githubusercontent.com/geerlingguy/mcrouter-operator/master/deploy/mcrouter-operator.yaml
After the operator starts (it takes a minute or two to start the operator containers which watch for CRs and changes), you can create Mcrouter resources. Check on the operator's status:
$ kubectl get deployment mcrouter-operator
NAME READY UP-TO-DATE AVAILABLE AGE
mcrouter-operator 1/1 1 1 67sNow deploy a Mcrouter resource:
cat <<EOF | kubectl apply -f -
apiVersion: mcrouter.example.com/v1alpha3
kind: Mcrouter
metadata:
name: mcrouter
spec:
memcached_pool_size: 3
pool_setup: replicated
EOFNote on namespaces: Currently Mcrouter Operator is configured to only watch for resources in the namespace it's inside (e.g.
default, in this example). You would need to modify themcrouter-operator.yamlfile to get it to deploy into another namespace if you want Mcrouter instances in that namespace. I'm considering changing this behavior, though, to make Mcrouter operator scoped to the entire cluster, so you can have one operator manage all instances across namespaces. See Operate cluster-wide, on all namespaces for the current status of this issue.
Now check on the status of the Mcrouter cluster you just deployed:
$ kubectl describe mcrouter
Name: mcrouter
...
Status:
Conditions:
Last Transition Time: 2019-09-11T22:14:41Z
Message: Running reconciliation
Reason: Running
Status: True
Type: Running
Events: <none>'Running reconciliation' means the operator is working to get the Mcrouter cluster in the state you described in the Mcrouter resource (3 memcached nodes, in a replicated pool). After a minute or two, you should see something like:
Status:
Conditions:
Ansible Result:
Changed: 0
Completion: 2019-09-11T22:15:33.720337
Failures: 0
Ok: 4
Skipped: 0
Last Transition Time: 2019-09-11T22:14:41Z
Message: Awaiting next reconciliation
Reason: Successful
Status: True
Type: Running
Events: <none>Successful means the Mcrouter cluster is in the proper working state, and you can start using it. Yay!
Using Mcrouter
Assuming you are outside the cluster, but can access ports on cluster servers, you can expose Mcrouter on a NodePort:
kubectl expose deploy/mcrouter --name mcrouter-nodeport --type=NodePort --target-port=5000
Now check the assigned nodeport with:
$ kubectl get svc mcrouter-nodeport
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
mcrouter-nodeport NodePort 10.106.213.91 <none> 5000:30534/TCP 82sVerify you can connect to the cluster with telnet (I installed it on my mac with brew install telnet):
telnet 192.168.64.13 30534
Trying 192.168.64.13...
Connected to 192.168.64.13.
Escape character is '^]'.
You can interact with memcached via its ASCII protocol; try entering stats and press enter, and you'll see the memcached statistics, along with some extra mcrouter statistics. Enter quit to exit the telnet session.
Benchmarks
There are many different ways to benchmark Mcrouter and Memcached. In this mcrouter-operator issue, I spent some time trying out Mcrouter with Wordpress (didn't work due to a library bug), Drupal (worked), and direct with a memcached benchmark utility, mcperf. Because of some slight differences in Mcrouter's protocol (vs. plain Memcached), it's hit or miss whether the standard libraries you use will 'just work' dropping in Mcrouter as a replacement.
Expose a mcrouter service internally using a ClusterIP on port 5000 (so you can access mcrouter at mcrouter:5000):
kubectl expose deploy/mcrouter --name mcrouter --type=ClusterIP --target-port=5000
Verify the mcrouter is accessible behind this service:
run -it --rm telnet --image=jess/telnet --restart=Never mcrouter 5000
Wait a few seconds then enter the stats command to see server stats, then quit to exit the telnet container.
Run mcperf to test Mcrouter's raw throughput:
kubectl run -it --rm mcperf --image=quay.io/redhat/mcperf --restart=Never -- -s mcrouter -p 5000 --linger=0 --timeout=5 --conn-rate=1000 --call-rate=1000 --num-calls=10 --num-conns=1000 --sizes=u1,16
I got the following results:
| Memcached setup | Requests per second |
|---|---|
| Mcrouter, replicated | 9851 |
| Mcrouter, sharded | 9884 |
| Single memcached instance, direct access | 9883 |
So in terms of running memcached through mcrouter on a single VM or a single server... it's not much of an improvement. Additionally, if you have a smaller application that wedges memcached between MySQL and your application for simple database object caching, the networking overhead of moving memcached (or mcrouter + memcached) further away from the database and application servers could actually result in worse performance.
But as with the decision to run MySQL on a server (or cluster) separate from your application server, the impetus is likely more around high availability, recoverability, and the ability to tune performance more precisely for a given workload. And in that case, as long as performance isn't worse (indeed, it's within 0.3% in my testing), the other benefits of Mcrouter proxying Memcached could very well make it worth trying!
Summary
The main objective of this blog post was to familiarize the reader with the Operator SDK for Kubernetes, demonstrating an operator built for managing a cache routing proxy. It's not likely most people will end up using Mcrouter or even Memcached (indeed, I often use Redis in my projects these days), but the utility of an Ansible-based Operator to manage an application or cluster inside Kubernetes is very appealing to me.
Instead of having to learn Go and the internals of Kubernetes' APIs, I can use familiar Ansible playbook and role structure, along with its simple but powerful k8s module, to build Kubernetes Operators to manage my apps.
If you want to dig a little deeper into another operator I've worked on, also check out my post A Drupal Operator for Kubernetes with the Ansible Operator SDK.