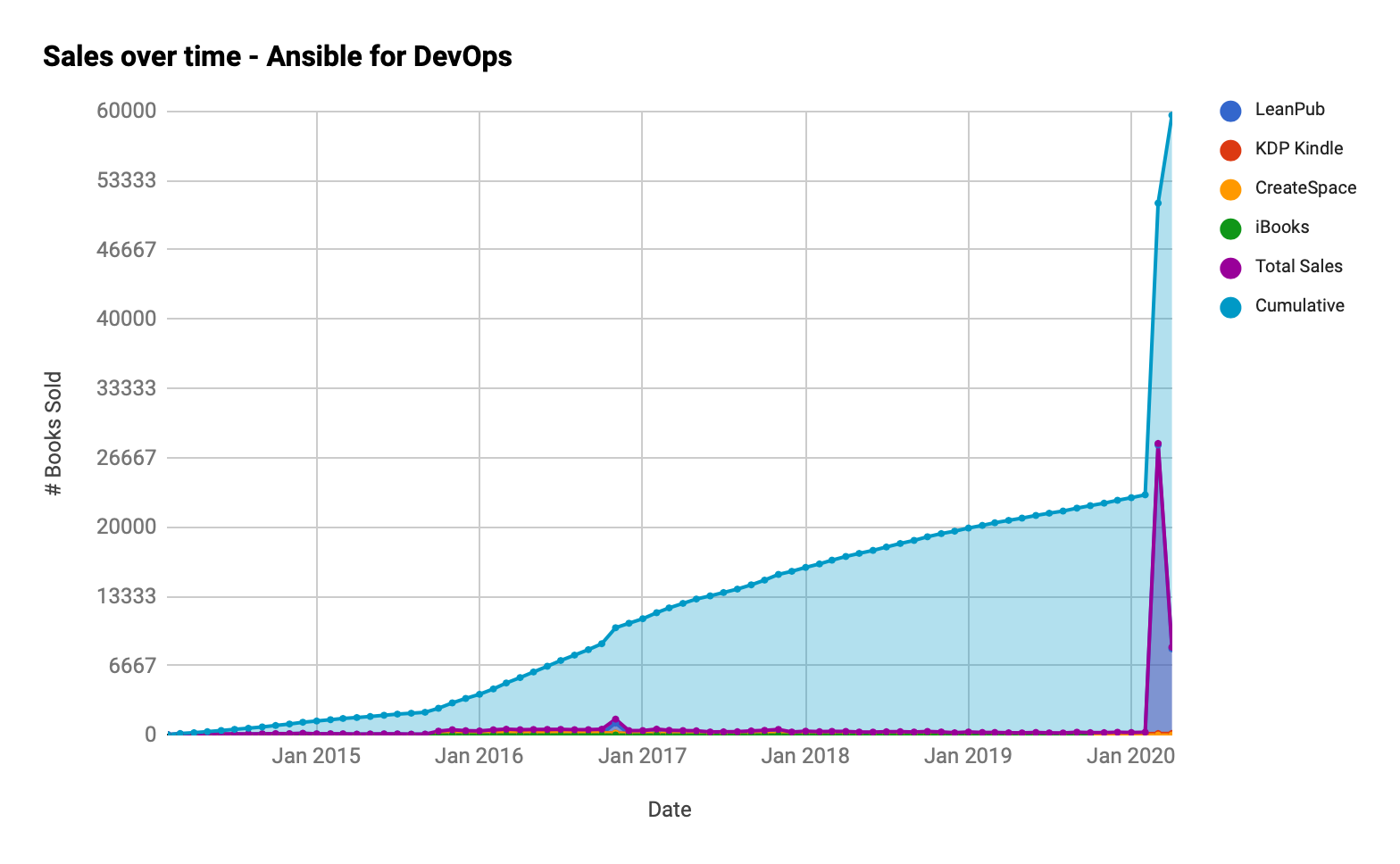
I gave away my books for free, and sales increased 4x
In March, I made my DevOps books free to help anyone who wanted to learn new skills during the global pandemic lockdown. In April, Device42 generously extended that offer for another month.
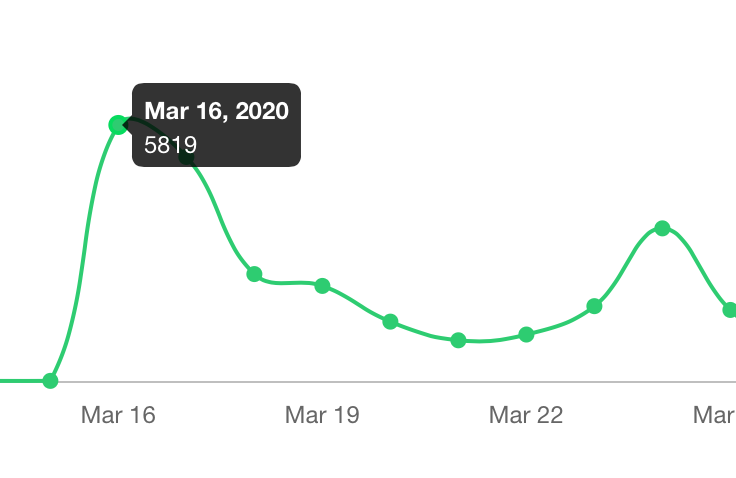
I originally had the idea to give the books away on a whim on a Sunday night, thinking I'd give up a fair chunk of revenue, but nothing too substantial. The response I did get was overwhelming, to say the least!
As with many other metrics during these unprecedented times, book sales shot through the roof while they were free. The top chart is Ansible for DevOps, and the bottom is Ansible for Kubernetes: