Late last year, OpenAI announced Whisper, a new speech-to-text language model that is extremely accurate in translating many spoken languages into text. The whisper repository contains instructions for installation and use.
tl;dr:
# Install whisper and its dependencies.
pip3 install git+https://github.com/openai/whisper.git
# (When needed) Update whisper.
pip3 install --upgrade --no-deps --force-reinstall git+https://github.com/openai/whisper.git
# Make sure ffmpeg is installed.
brew install ffmpeg
# Translate speech into text.
whisper my_audio_file.mp3 --language English
One thing I do quite regularly for my YouTube channel is extract the audio track, convert it to text using an online tool (I used to use Welder until they were bought out by Veed), and then hand-edit the file to fix references to product names, people, etc.
Then I upload either an edited .txt or .srt file alongside my video on YouTube, and people are able to use Closed Captions. YouTube shows whether a video has manually-curated captions with this handy little 'CC' icon:
But as Veed's free tier only allows up to 10 minutes of audio to be transcribed at a time, it was time to look elsewhere. And on my earlier blog post about using macOS's built-in Dictation feature for transcription, rasmi commented that a new tool was available, Whisper.
So I took it for a spin!
I installed it and ran it on one of my video's audio tracks using the commands at the top of this post, and I was pleasantly surprised:
- Experimenting with the different models,
base.enwas very fast for English, but I found thatsmallormediumwere much better at identifying product names, obscure technical terms, etc. Honestly it blew me away that it picked up words like 'PlinkUSA', 'Sliger', and 'Raspberry Pi'—something other transcription tools would trip on. - You can even translate text files (using
--translate), which is a neat trick. It will automatically identify the source language, or you can specify it with--language). - It's not quite perfect yet—I still need to touch up probably one word every 10 sentences. But it's a thousand times easier than trying to transcribe things manually! And it even does punctuation and outputs an .srt natively.
I've been scanning through discussions and there are already some great ones about features like diarization (being able to identify multiple speakers in a conversation) and performance benchmarking.
On my Mac Studio's CPU, the conversion process is only a little slower than real-time. I haven't yet tested it on my PC with a beefier GPU, but I plan on testing that soon.
Being fairly new, specific UIs for Whisper aren't mature yet... but I did find things like whisper-ui, and there's even a Hugging Face webapp Whisper Webui you can use for up to 10 minutes of audio transcription to get a feel for it.
And on macOS, if the command line isn't your thing, Jordi Bruin created an app MacWhisper, which is free for the standard version and includes a UI for editing the transcription live:
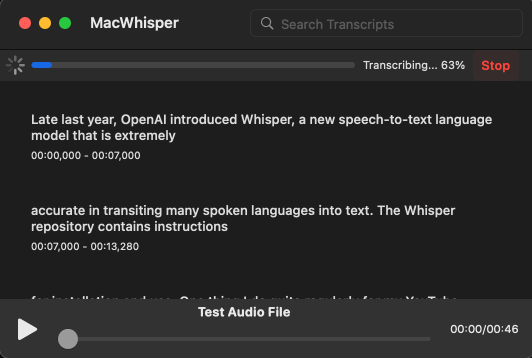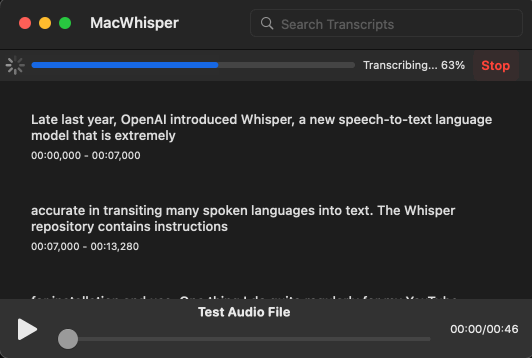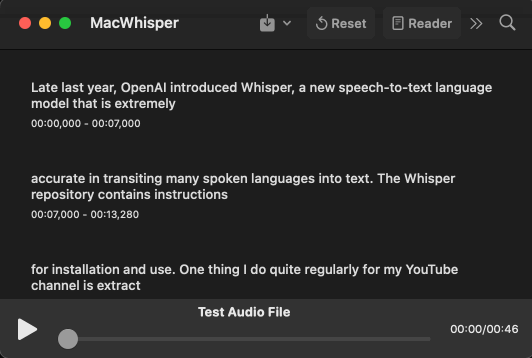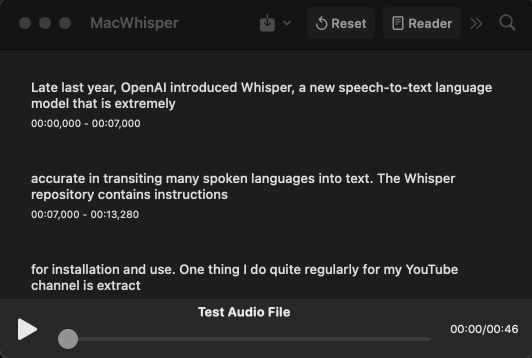
Hopefully more UIs are developed, especially something I could toss on one of my PCs here, so I could quickly throw an audio file at it from any device.
I'm generally a bit conservative when it comes at throwing AI at a problem, but speech to text (and vice-versa) is probably one of the most cut-and-dry uses that makes sense and doesn't carry a number of footguns.
Comments
Interesting. What do you use to isolate your python environments with the different libraries etc, e.g. the pip3 installs you're doing above?
I've used brew version of python3 and been burnt before with pyenv when a new version of python3 hit the brew repositories, breaking everything.
Or do you just put it all in a docker container to isolate everything?
I just use vanilla Python 3 and pip3 installed via homebrew on my Mac. I often reset the environment completely (like when upgrading from Python 3.8 to 3.9), so it's not an issue for me, really.
If it's more fragile, I'll pack it up into a Dockerfile and build a container for the application.
Try pipx. It is perfect for one-off python executables.
pipx install --python /opt/homebrew/bin/python3.10 git+https://github.com/openai/whisper.git
I haven't tried it, but you might try the self-hosted 'whisper-as-a-service' project on github https://github.com/schibsted/WAAS
I played around with using Whisper to transcribe amateur radio transmissions. We have this thing called reverse beacon network (https://www.reversebeacon.net/) which listens to morse and digital signals for CQ calls and posts the "transcription" of the CQ call to a database. That makes it easy to find new stations, and saves a lot of time for the CQ caller. However, it obviously doesn't work for voice modes (like single sideband). Whisper was surprisingly good at transcribing intelligible SSB audio (> 10dB SNR), but trips up with callsigns since they're usually phonetic (alpha bravo romeo etc). Just a little work and we could have an RBN for voice.
I bet a little pre and post processing would help a lot. You could use an initial_prompt[0] like "This is a radio transmission.". You could do a regex for call signs after if it's getting the words right but not formatting them correctly. You could also send it to GPT-3 for cleanup. I've had that work well. Of course, you're not as cheap or local anymore at that point. The serious move would be to fine tune a model, but that's a lot of work for unknown reward.
[0] https://github.com/openai/whisper/discussions/963
You might find whisper.cpp helpful (https://github.com/ggerganov/whisper.cpp)
It uses optimized Neon instructions for Arm, is apparently "wicked fast", and could be used as part of a pipeline of some kind.
I am unable to run the large model locally but was currious how it compared with medium. I was able to load it on Colab's GPU for a quick comparison. Large ran at about 1.5x realtime. One would need to pay for the service if used regularely. Neat to have on hand for occasional use.
Whisper is awesome, thanks for sharing!
I got to use Whisper earlier this week to add English subtitles on a recorded meeting of some coworkers that were speaking Turkish when presenting a technical walk through of setting up some systems.
It was amazing being able to take something that I couldn’t understand to being able to have subtitles in my language and follow along with the recorded presentation without needing someone to re-present it in a language I can understand.
I took the details a college originally figured out and wrote, then I packaged the details into a gist for easy reference. https://gist.github.com/mttjohnson/31e9fe018c39bde826ae543bcd0007a7
Defiantly going to try that.
Also trying this out but running into an issue with a mp3 file created with Audio Hijack. It was a recorded FaceTime call and Whisper only appears to transcribe my part of the conversation. Not sure if I have missed a setting, but can transcribe the same file in Drafts.app without a problem.
same here, have you found an answer ?
thanks
I my do I feel stupid. I never Git before. So now I did pip3 git+... and now where are those files on my MacBook? And how do I get rid of them again? I can use Whisper from commandline - so thanks for that, but I like to know where my stuff goes.
Great article, thanks. I'll try the tool
Not a techie guy, but I was originally googling how to create an srt file from mp3 or mp4 and not how to convert a memo into text.
Funny how the whole set of tools is different depending how you google it. It's pretty much the same thing/logic, right?
Thanks again