I started Hosted Apache Solr almost 10 years ago, in late 2008, so I could more easily host Apache Solr search indexes for my Drupal websites. I realized I could also host search indexes for other Drupal websites too, if I added some basic account management features and a PayPal subscription plan—so I built a small subscription management service on top of my then-Drupal 6-based Midwestern Mac website and started selling a few Solr subscriptions.
Back then, the latest and greatest Solr version was 1.4, and now-popular automation tools like Chef and Ansible didn't even exist. So when a customer signed up for a new subscription, the pipeline for building and managing the customer's search index went like this:
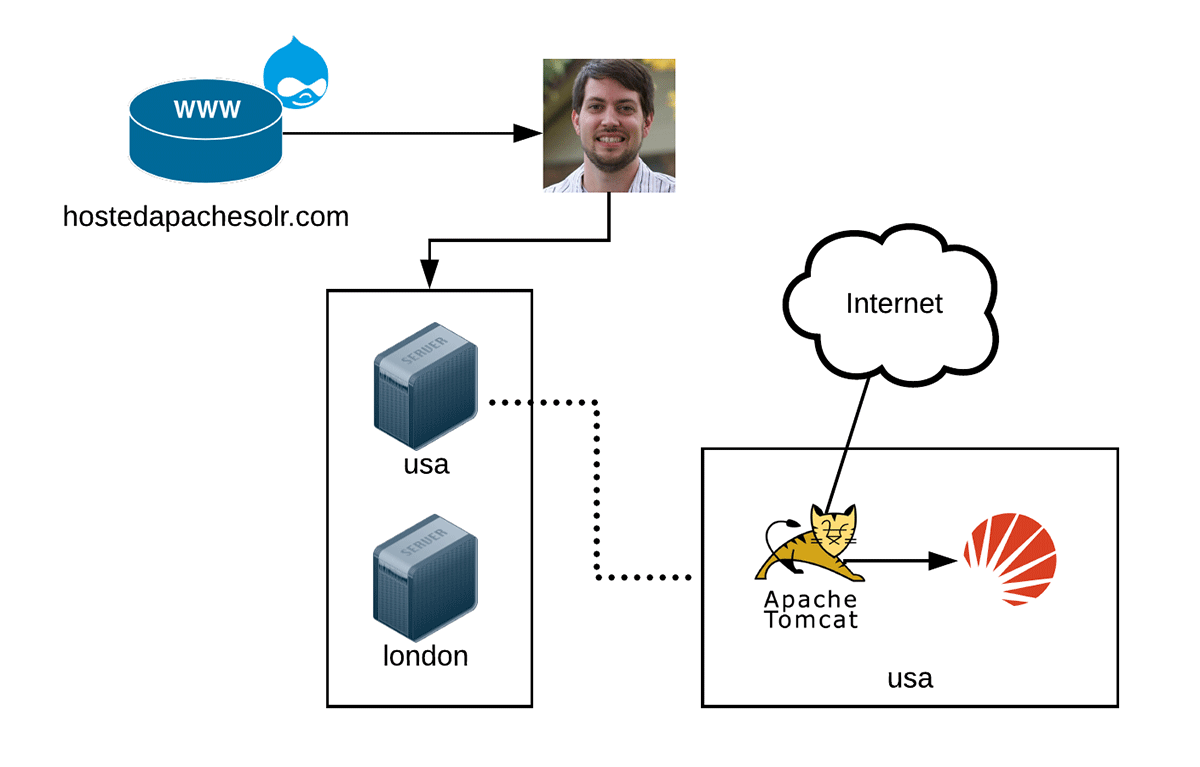
Original Hosted Apache Solr architecture, circa 2009.
Hosted Apache Solr was run entirely on three servers for the first few years—a server running hostedapachesolr.com, and two regional Apache Solr servers running Tomcat and Apache Solr 1.4. With three servers and a few dozen customers, managing everything using what I'll call GaaS ("Geerlingguy as a Service") was fairly manageable.
But fast forward a few years, and organic growth meant Hosted Apache Solr was now spread across more than 10 servers, and Apache Solr needed to be upgraded to 3.6.x. This was a lot more daunting of an upgrade, especially since many new customers had more demanding needs in terms of uptime (and a lot more production search traffic!). This upgrade was managed via shell scripts and lots of testing on a staging server, but it was a little bit of a nail-biter to be sure. A few customers had major issues after the upgrade, and I learned a lot from the experience—most especially the importance of automated and fast backup-and-restore automation (it's not good enough to just have reliable backups!).
It was around the time of Apache Solr 4.6's release when I discovered Ansible and started adopting it for all my infrastructure automation (so much so that I eventually wrote a book on Ansible!). For the Apache Solr 3.6 to 4.6 upgrade, I used an Ansible playbook which allowed me better control over the rollout process, and also made it easier to iterate on testing everything in an identical non-production environment.
But at that time, there were still a number of infrastructure operations which could be classified as 'GaaS', and took up some of my time. Wanting to optimize the infrastructure operations even further meant I needed to automate more, and start changing some architecture to make things more automate-able!
So in 2015 or so, I conceived an entirely new architecture for Hosted Apache Solr:
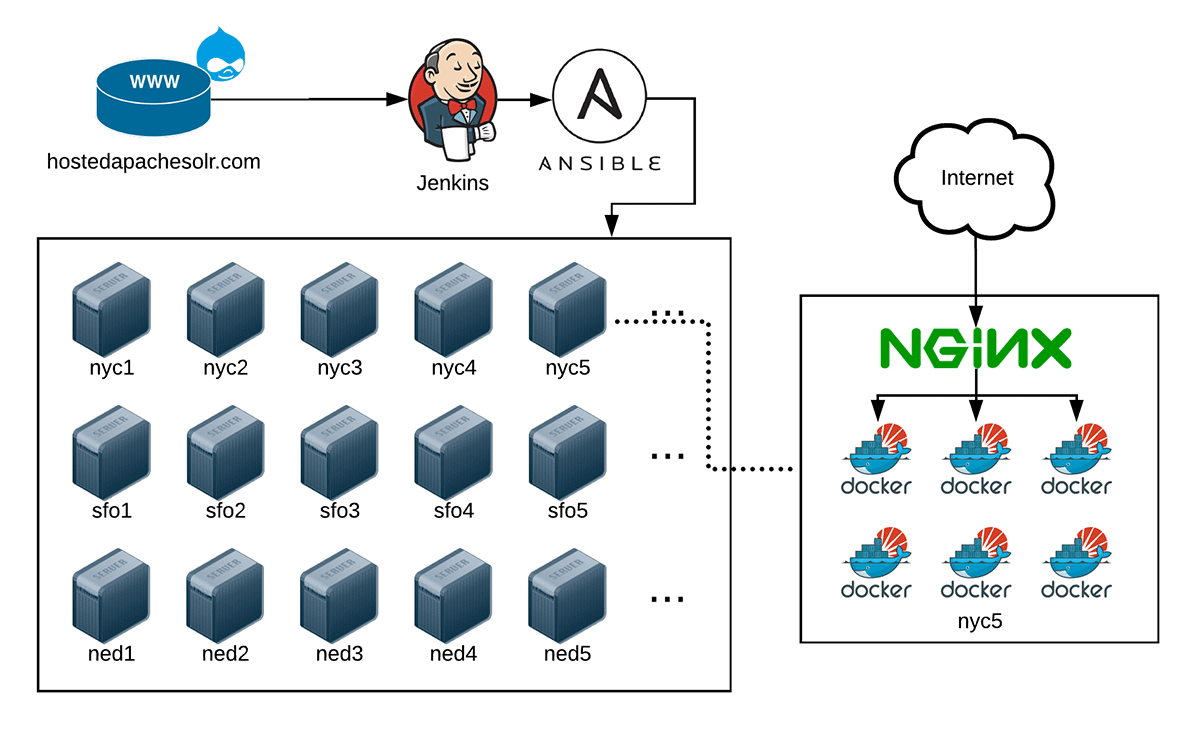
Docker was still new and changing rapidly, but I saw a lot of promise in terms of managing multiple search subscriptions with more isolation, and especially with the ability to move search indexes between servers more efficiently (in a more 'clustered' environment).
Unfortunately, life got in the way as I have multiple health-related problems that robbed me of virtually all my spare time (Hosted Apache Solr is one of many side projects, in addition to my book (Ansible for DevOps), Server Check.in, and hundreds of open source projects).
But the architecture was sound in 2015, even though—at the time—Docker was still a little unstable. In 2015, I had a proof of concept running which allowed me to run multiple Docker containers on a single server, but I was having trouble getting requests routed to the containers, since each one was running a separate search index for a different client.
Request routing problems
One major problem I had to contend with was a legacy architecture design where each client's Drupal site would connect directly to one of the servers by hostname, e.g. "nyc1.hostedapachesolr.com", or "nyc2.hostedapachesolr.com". Originally this wasn't a major issue as I had few servers and would scale individual 'pet' servers up and down as capacity dictated. But as the number of servers increases, and capacity needs fluctuate more and more, this has become a real pain point; mostly, it makes it hard for me to move a client from one server to another, because the move needs to be coordinated with the client and can't be dynamic.
To resolve this problem, I decided to integrate Hosted Apache Solr's automation with AWS' Route53 DNS service, which allows me to dynamically assign a new CNAME record to each customer's search index—e.g. instead of nyc1.hostedapachesolr.com, a customer uses the domain customer-subscription.hostedapachesolr.com to connect to Hosted Apache Solr. If I need to move the search index to another server, I just need to re-point customer-subscription.hostedapachesolr.com to another server after moving the search index data. Problem solved!
Another problem had to do with authentication: Hosted Apache Solr has used IP-based authentication for search index access since the beginning. Each client's search index is firewalled and only accessible by one or more IP addresses, configured by the client. This is a fairly secure and recommended way to configure access for Apache Solr search, but there are three major problems with this approach:
- Usability: Clients had to discover their servers' IP address(es), and enter them into their subscription details. This creates friction in the onboarding experience, and can also cause confusion if—and this happens a lot—the actual IP address of the server differs from the IP address their hosting provider says is correct.
- Security: A malicious user with a valid subscription could conceivably spoof IP addresses to gain access to other clients search indexes, provided they're located on the same server (since multiple clients are hosted on a single server, and the firewall was on the server level).
- Cloud Compatibility: Many dynamic Cloud-based hosting providers like AWS, Pantheon, and Platform.sh allocate IP addresses to servers dynamically, and a client can't use one stable IP address—or even a range of IP addresses—to connect to Hosted Apache Solr's servers.
Luckily, there's a second way to provide an authentication layer for Apache Solr indexes, and that's HTTP Basic Authentication. And HTTP Authentication is well supported by all versions of Drupal's Apache Solr modules, as well as almost all web software in existence, and it resolves all three of the above issues!
I settled on using Nginx to proxy all web requests to the Solr backends, because using server directives, I could support both dynamic per-customer hostnames, as well as HTTP Authentication, using Nginx configuration like:
server {
listen 80;
server_name customer-subscription.hostedapachesolr.com;
auth_basic "Connection requires authentication.";
auth_basic_user_file /path/to/htpasswd-file;
location / {
proxy_pass http://127.0.0.1:[solr-port];
}
}Each customer gets a Solr container running on a specific port (solr-port), with a unique hostname and a username and password stored on the server using htpasswd.
Good migrations
This new architecture worked great in my testing, and was a lot easier to automate (it's always easier to automate something when you have a decade of experience with it and work on a greenfield rewrite of the entire thing...)—but I needed to support a large number of existing customers, ideally with no changes required on their end.
That's a tall order!
But after some more medically-induced delays in the project in 2017 and early 2018, I finally had the time to work on the migration/transition plan. I basically had to:
- Build an Ansible playbook to backup a Solr server, delete it, build a new one with the same hostname, then restore all the existing client Solr index data, with as little downtime as possible.
- Support IP-based authentication for individual search indexes during a transition period.
- Build functionality into the Drupal hostedapachesolr.com website which allows the customer to choose when to transition from IP-based authentication to HTTP Basic Authentication.
The first task was the most straightforward, but took the longest; migrating all the data for dozens of servers with minimal downtime while completely rebuilding them all is a bit of a process, especially since the entire architecture for the new version was different. It required a lot of testing, and I tested against an automated test bed of 8 Drupal sites, across Drupal 6, 7, and 8, running all the popular Apache Solr connection modules with a variety of configurations.
For IP-based authentication, I wrote some custom rules in an Nginx server directive that would route requests from certain IP addresses or IP ranges to a particular Solr container; this was fairly straightforward, but I spent a bit of time making sure that having a large number of these legacy routing rules wouldn't slow down Nginx or cause any memory contention (luckily, they didn't, even when there were hundreds of them!).
Finally, after I completed the infrastructure upgrade process, I worked on the end-user-facing functionality for upgrading to the new authentication method.
Letting the customer choose when to transition
Learning from past experience, it's never nice to automatically upgrade clients to something newer, even after doing all the testing you could possibly do to ensure a smooth upgrade. Sometimes it may be necessary to force an upgrade... but if not, let your customers decide when they want to click a button to upgrade.
I built and documented the simple upgrade process (basically, edit your subscription and check a box that says "Use HTTP Basic Authentication"), and it goes something like:
- User updates subscription node in Drupal.
- Drupal triggers Jenkins job to update the search server configuration.
- Jenkins runs Ansible playbook.
- Ansible adds a Route53 domain for the subscription, updates the server's Nginx configuration, and restarts Nginx.
The process again worked flawlessly in my testing, with all the different Drupal site configurations... but in any operation which involves DNS changes, there's always a bit of an unknown. A few customers have reported issues with the length of time it takes for their Drupal site to re-connect after updating the server hostname, but most customers who have made the upgrade have had no issues and are happy to stop managing server IP addresses!
Why not Kubernetes?
A few people who I've discussed architecture with almost immediately suggested using Kubernetes (or possibly some other similarly-featured container orchestration/scheduler layer). There are a couple major reason I have decided to stick with vanilla docker containers and a much more traditional scheduling approach (assign a customer to a particular server):
- Legacy requirements: Currently, most clients are still using the IP-based authentication and pointing their sites at the servers directly. Outside of building a complex load balancing/routing layer on top of everything else, this is not that easy to support with Kubernetes, at least not for a side project.
- Complexity: I'm working on my first Kubernetes-in-production project right now (but for pay, not for a side hustle), and building, managing, and monitoring a functional Kubernetes environment is still a lot of work. Way too much for something that I manage in my spare time, and expect to maintain 99.9%+ uptime through a decade!
Especially considering many Kubernetes APIs on which I'd be reliant are still in alpha or beta status (though many use them in production), the time's not yet ripe for moving a service like Hosted Apache Solr over to it.
Summary and Future plans
Sometimes, as a developer, working on new 'greenfield' projects can be very rewarding. No technical debt to manage, no existing code, tests, or baggage to deal with. You just pick what you think is the best solution and soldier on!
But upgrading projects like Hosted Apache Solr—with ten years of baggage and an architecture foundation in need of a major overhaul—can be just as rewarding. The challenge is different, in terms of taking an existing piece of software and transforming it (versus building something new). The feeling of satisfaction after a successful major upgrade is the same as I get when I launch something new... but in some ways it's even better because an existing audience (the current users) will immediately reap the benefits!
The new Hosted Apache Solr infrastructure architecture has already made automation and maintenance easier, but there are some major client benefits in the works now, too, like allowing clients to choose any Solr version they want, better management of search indexes, better statistics and monitoring, and in the future even the ability to self-manage configuration changes!
Finally... if you need to supercharge your Drupal site search, consider giving Hosted Apache Solr a try today :)
Comments
I appreciate your thoughts on Ansible and Kubernetes. When we first started working on the architecture for Aegir 5 (host anything, not just Drupal sites!), we needed a replacement for Drush, the back-end tool that traditionally does the heavy lifting. Although we had a working Kubernetes prototype (https://gitlab.com/aegir/hosting_kubernetes), we thought we'd start with Ansible, but keep it pluggable so that we could swap in Kubernetes later. There would have been a lot more overhead with Kubernetes so I'm glad we didn't jump there right away.
The Aegir 5 architecture can be found at https://gitlab.com/aegir/aegir/wikis/architecture. While we don't quite have something to play with just yet (but keep an eye on https://gitlab.com/aegir/aegir and https://www.aegirproject.org/), we're hoping to have something soon.
Fantastic read. Many thanks for documenting your process.