Fixing nginx Error: Undefined constant PDO::MYSQL_ATTR_USE_BUFFERED_QUERY
I install a lot of Drupal sites day to day, especially when I'm doing dev work.
In the course of doing that, sometimes I'll be working on infrastructure—whether that's an Ansible playbook to configure a Docker container, or testing something on a fresh server or VM.
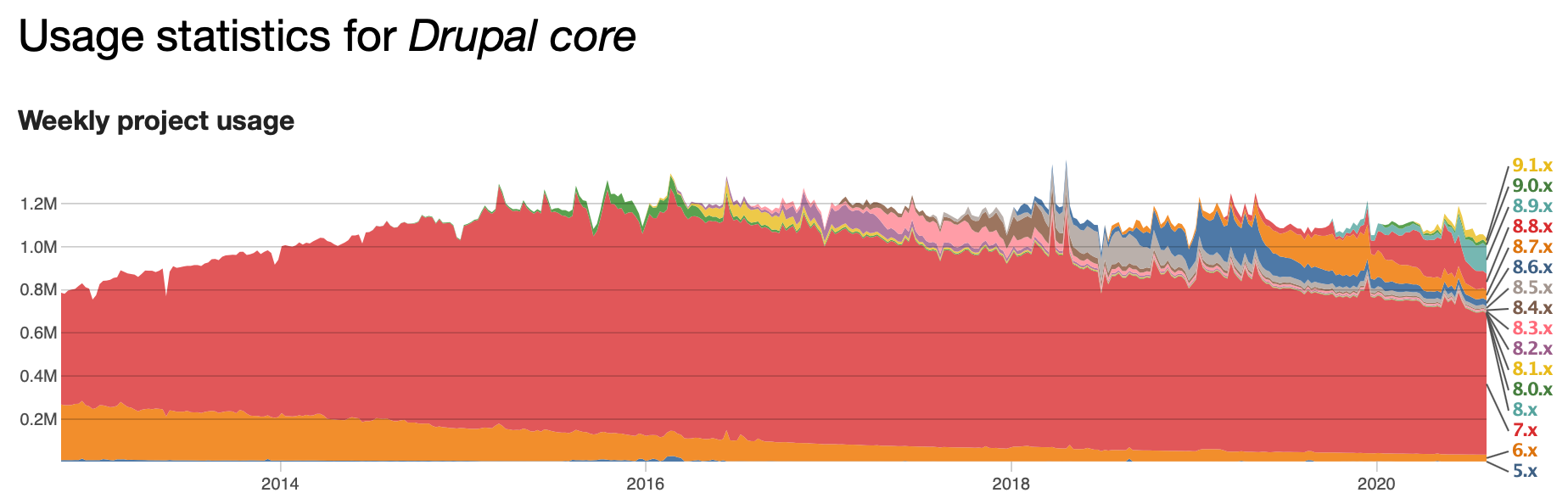
In any case, I run into the following error every so often in my Nginx error.log:
"php-fpm" nginx Error: Undefined constant PDO::MYSQL_ATTR_USE_BUFFERED_QUERY
The funny thing is, I don't have that error when I'm running CLI commands, like vendor/bin/drush, and can even install and manage the Drupal site and database on the CLI.
The problem, in my case, was that I had applied php-fpm configs using Ansible, but in my playbook I hadn't restarted php-fpm (in my case, on Ubuntu 22.04, php8.3-fpm) after doing so. So FPM was running with outdated config and didn't know that the MySQL/MariaDB drivers were even present on the system.