This blog post contains a written transcript of my NEDCamp 2018 keynote, Real World DevOps, edited to match the style of this blog. Accompanying resources: presentation slides, video.

I'm Jeff Geerling; you probably know that because my name appears in huge letters at the top of every page on this site, including the post you're reading right now. I currently work at Acquia as a Senior Technical Architect, building hosting infrastructure projects using some buzzword-worthy tech like Kubernetes, AWS, and Cloud.
I also maintain Drupal VM, the most popular local development environment for the Drupal open source CMS. And I run two SaaS products with hundreds of happy customers, Hosted Apache Solr and Server Check.in, both of which have had over 99.99% uptime since their inception for a combined 15 years. I also write (and continuously update) a best-selling book on Ansible, Ansible for DevOps, and a companion book about Kubernetes. Finally, I maintain a large ecosystem of Ansible roles and automation projects on GitHub which have amassed over 17,000 stars and 8,000 forks.
Oh, I also have three children under the age of six, have a strong passion for photography (see my Flickr), maintain four Drupal websites for local non-profit organizations, and love spending time with my wife.
You might be thinking: this guy probably never spends time with his family.
And, if you're speaking of this weekend, sadly, you'd be correct—because I'm here in Rhode Island with all of you!
But on a typical weeknight, I'm headed upstairs around 5-6 p.m., spend time with my family for dinner, after-meal activities, prayers, and bedtime. And on weekends, it's fairly rare I'll need to do any work. We go to the zoo, we go on family trips, we go to museums, and we generally spend the entire weekend growing together as a family.
Some nights, after the kids are settled in bed, I'll spend an hour or two jumping through issue queues, updating a section of my book—or, as is the case right now, writing this blog post.
How do I do it?
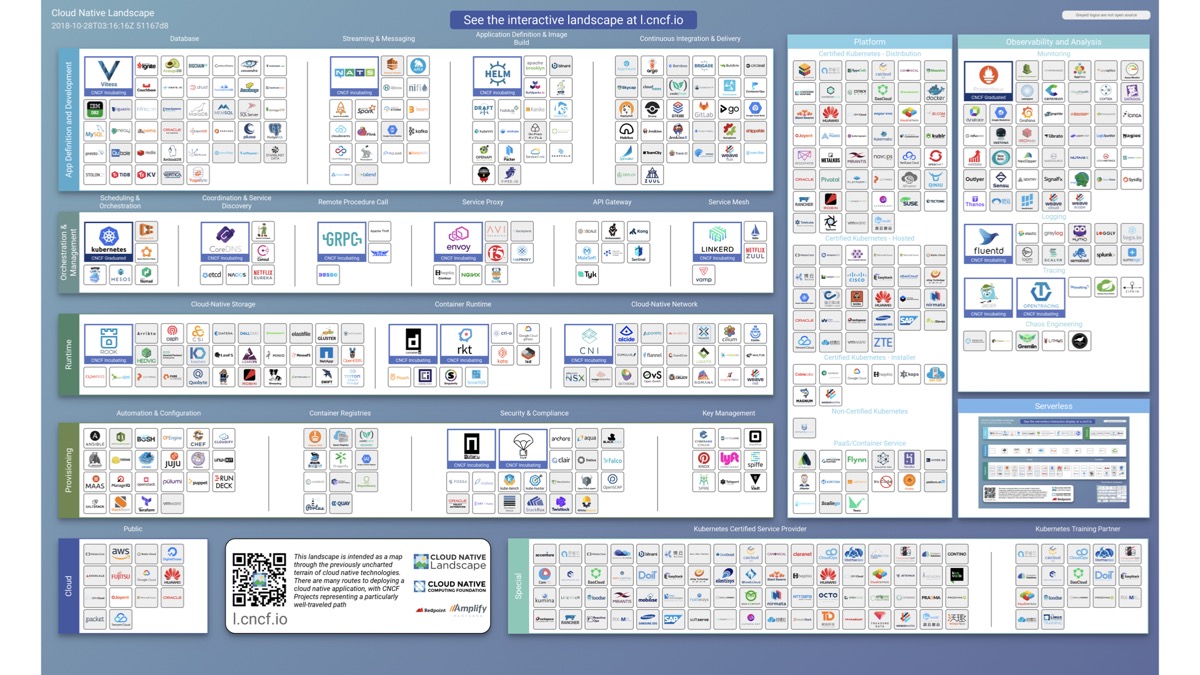
Well I apply complex self-healing, highly-scalable DevOps architectures to all my projects using all the tools shown in this diagram! I'm kidding, that would be insane. But have you seen this graphic before? It's the Cloud Native Landscape, published by the Cloud Native Computing Foundation.
The reason I show this picture is because I expect everyone reading this to memorize all these tools so you know how to implement DevOps by next week.
Just kidding again! Some people think the mastery of some tools in this diagram means they're doing 'DevOps'. To be honest, you might be practicing DevOps better than someone who integrates fifty of these tools using nothing but Apache and Drupal—neither of which are listed in this infographic!
What is DevOps?
The framework I use is what I call 'Real World DevOps'. But before I get into my definition, I think it's important we understand what the buzzword 'DevOps' means, according to our industry:
Microsoft, apparently, packaged up DevOps and sells it as part of Azure's cloud services. So you can put a price on it, apparently, get a purchase order, and have it! Right?

And I see a lot of DevOps people talk about how Docker transformed their developers into amazing coding ninjas who can deploy their code a thousand times faster. So Docker is part of DevOps, right?

And to do DevOps, you have to be in the cloud, because that's where all DevOps happens, right?

And DevOps requires you to strictly follow Agile methodologies, like sprints, kanban, scrums, pair programming, and pointing poker, right?
Well, let's go a little further, and see what some big-wigs in the industry have to say:
"People working together to build, deliver, and run resilient software at the speed of their particular business."
—GitLab
So it sounds like there's a people component, and some sort of correlation between speed and DevOps.
Okay, how about Atlassian?
DevOps "help[s] development and operations teams be more efficient, innovate faster, and deliver higher value"
—Atlassian
So it sounds like it's all about making teams better. Okay...
"Rapid IT service delivery through the adoption of agile, lean practices in the context of a system-oriented approach"
—Gartner
(Oh... that's funny, this quote is also in one of O'Reilly's books on DevOps, in a post from Ensono, and in basically every cookie-cutter Medium post about DevOps.)
In Gartner's case, they seem to focus strongly on methodology and service delivery—but that's probably because their bread and butter is reviewing products which purportedly help people track methodology and service delivery! It's interesting (and telling) there's no mention about people or teams!
But what do I say about DevOps?
But what about me? I just claimed to practice DevOps in my work—heck, my book has the word DevOps in the title! Surely I can't just be shilling for the buzzword profit multiplier by throwing the word 'DevOps' in my book title... right?

Well, to be honest, I did use the word to increase visibility a bit. Why else do you think my second book has the word 'Kubernetes' in it!?
But my definition of DevOps is a bit simpler:

"Making people happier while making apps better."
—Jeff Geerling (Photo above by Kevin Thull)
I think this captures the essence of real world, non-cargo-cult DevOps, and that's because it contains the two most important elements:
Making people happier
DevOps is primarily about people: every team, no matter the size, has to figure out a way to work together to make users happy, and not burn out in the process. And what are some of the things I see in teams that are implementing DevOps successfully?
- Reduced friction between Operations/sysadmins, Developers, Project Management, InfoSec, and QA. People don't feel like it's 'us against them', or 'we will loop them in after we finish our part'. Instead, everyone talks, everyone has open communication lines in email or Slack, and requirements and testing are built up throughout the life of the project.
- Reduced burnout, because soul-sucking problems and frustrating communications blockades are almost non-existent.
- Frequent code deploys, and almost always in the middle of the workday—and this also feeds back into reduced burnout, because nobody's pulling all-nighters fixing a bad deploy and wrangling sleepy developers to implement hotfixes.
- Stable teams that stay together and grow into a real team, not just a 'project team'; note that this can sometimes be impossible (e.g. in some agency models), but it does make it easier to iteratively improve if you're working with the same people for a long period of time.
- There are no heroes! Nobody has to be a rockstar ninja, working through the weekend getting a release ready, because DevOps processes emphasize stability, enabling a better work-life balance for everyone on the team.
How many times have you seen an email praising the heroic efforts of the developer who fixed some last-minute major issues in a huge new feature that were discovered in final user acceptance testing? This should not be seen as a heroic deed—rather it should be seen as a tragic failure. Not a failure of the developer, but as a failure of the system that enabled this to happen in the first place!
DevOps is about making people happier.
Making apps better
Devops is also about apps: you can't afford to develop at a glacial pace in the modern world, and when you make changes, you should be confident they'll work. Some of the things I see in the apps that are built with a DevOps mentality include:
- Continuous delivery: a project's master (or production) code branch is always deployable, and passes all automated tests—and there are automated tests, at least covering happy paths.
- Thorough monitoring: teams know when deployments affect performance. They know whether their users are having a slow or poor experience. They get alerts when systems are impaired but not down.
- Problems are fixed as they occur. Bugfixes and maintenance are part of the regular workflow, and project planning gives equal importance to these issues as it does features.
- Features are delivered frequently, and usually in small increments. Branches or unmerged pull requests rarely last more than a few days, and never more than a sprint.
Small but frequent deployments are one of the most important ways to make your apps better, because it also makes it easier to fix things as problems occur. Instead of dropping an emergent bug into a backlog, and letting it fester for weeks or months before someone tries to figure out how to reproduce the bug, DevOps-empowered teams 'swarm' the bug, and prevent similar bugs from ever happening again by adding a new test, correcting their process, or improving their monitoring.
DevOps is about making apps better.
DevOps Prerequisites
So we know that DevOps is about people and apps, and we know some of the traits of a team that's doing DevOps well, but are there some fundamental tools or processes essential to making DevOps work? Looking around online, I've found most DevOps articles mention these prerequisites:
- Automation
- CI/CD
- Monitoring
- Collaboration
I tend to agree that these four traits are essential to implementing DevOps well. But I think we can distill the list even further—and in some cases, some prerequisites might not be as important as the others.
I think the list should be a lot simpler. To do DevOps right, it should be:
- Easy to make changes
- Easy to fix and prevent problems (and prevent them from happening again)
Easy to make changes
I'm just wondering: have you ever timed how long it takes for a developer completely new to your project to get up and running? From getting access to your project codebase and being able to make a change to it locally? If not, it might be a good idea to find out. Or just try deleting your local environment and codebase entirely, and starting from scratch. It should be very quick.
If it's not easy and fast to start working on your project locally, it's hard to make changes.
Once you've made some changes, how do you know you won't break any existing functionality on your site? Do you have behavioral testing that you can easily run, and doesn't take very long to run, and doesn't require hours of setup work or a dedicated QA team? Do you have visual regression tests which verify that the code you just changed won't completely break the home page of your site?
If you can't be sure your changes won't break things, it's scary to make changes.
Once you deploy changes to production, how hard is it to revert back if you find out the changes did break something badly? Have you practiced your rollback procedure? Do you even have a process for rollbacks? Have you tested your backups and have confidence you could restore your production system to a known good state if you totally mess it up?
If you can't back out of broken changes, it's scary to make changes.
The easier and less stressful it is to make changes, the more willing you'll be to make them, and the more often you'll make them. Not only that, with more confidence in your disaster recovery and testing, you'll also be more confident and less stressed.
"High performers deployed code 30x more frequently, and the time required to go from “code committed” to “successfully running in production” was 200x faster."
—The DevOps Handbook
While you might not be deploying code 300 times a day, you'll be happy to deploy code whenever you want, in the middle of the workday, if you can make changes easy.
Easy to fix and prevent problems
Making changes has to be easy, otherwise it's hard to fix and prevent problems. But that's not all that's required.
Are developers able to deploy their changes to production? Or is there a long, drawn out process to get a change deployed to production? If you can build the confidence that at least the home page still loads before the code is deployed, then you'll be more likely to make small but frequent changes—which are a lot easier to fix than huge batches of changes!
Developers should be able to deploy to production after their code passes tests.
Once you deploy code, how do you know if it's helping or hurting your site's performance? Do you have detailed metrics for things like average end-user page load times (Application Performance Monitoring, or APM), CPU usage, memory usage, and logs? Without these metrics you can't make informed decisions about what's broken, or whether a particular problem is fixed.
Detailed system metrics and logging is essential to fix and prevent problems.
When something goes wrong, does everyone duck and cover, finding ways to avoid being blamed for the incident? Or does everyone come together to figure out what went wrong, why it went wrong, and how to prevent it from happening in the future? It's important that people realize when something goes wrong, it's rarely the fault of the person who wrote the code or pressed the 'go' button—it's the fault of the process. Better tests, better requirements, more thorough reviews would prevent most issues from ever happening.
'Blameless postmortems' prevent the same failure from happening twice while keeping people happy.
DevOps Tools
But what about tools?
"It's a poor craftsman that blames his tools."
—An old saying
Earlier in this post I mentioned that you could be doing DevOps even if you don't use any of the tools in the Cloud Native Landscape. That may be true, but you should also avoid falling into the trap of having one of these:

A golden hammer is a tool that someone loves so much, they use it for purposes for which it isn't intended. Sometimes it can work... but the results and experience are not as good as you'd get if you used the right tool for the job. I really like this quote I found on a Hacker News post:
"Part of being an expert craftsman is having the experience and skills to select excellent tools, and the experience and skills to drive those excellent tools to produce excellent results."
—jerf, HN commenter
So a good DevOps practitioner knows when it's worth spending the time learning how to use a new tool, and when to stick with the tools they know.
So now that we know something about DevOps, here's a project for you: build some infrastructure for a low-profile Drupal blog-style site for a budget-conscious client with around 10,000 visitors a day. Most of the traffic comes from Google searches, and there is little authenticated traffic. What would you build?
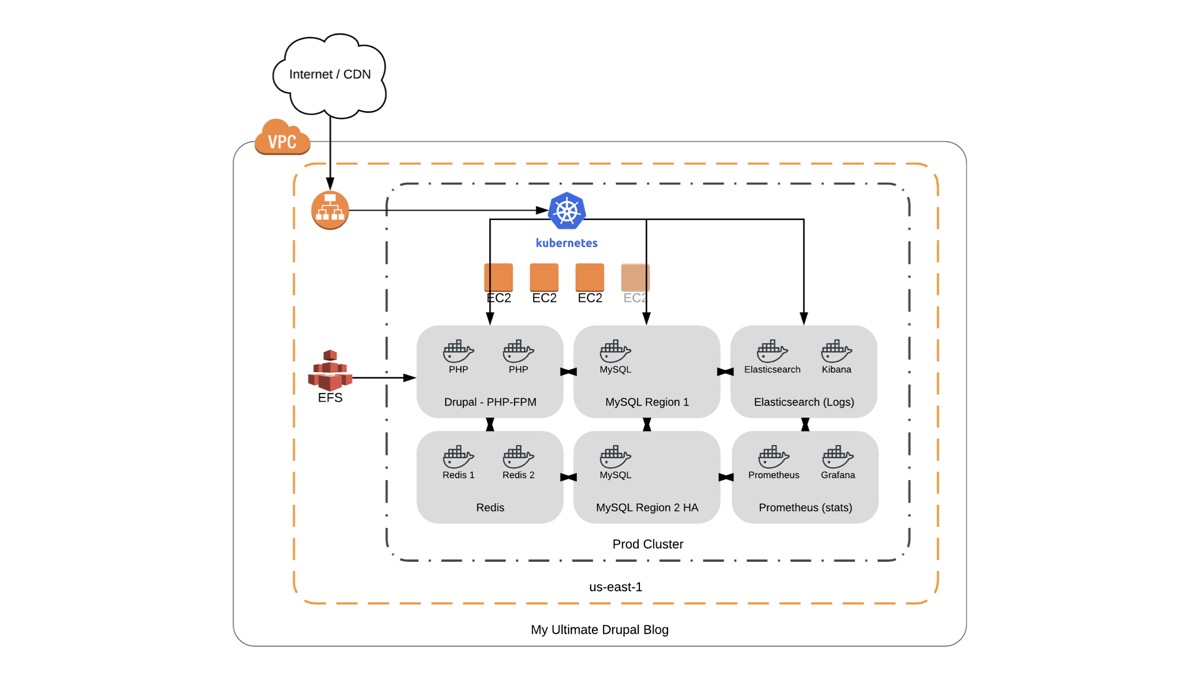
Wow! That looks great! And it uses like 20 CNL projects, so it's definitely DevOps, right?
Great idea, terrible execution.
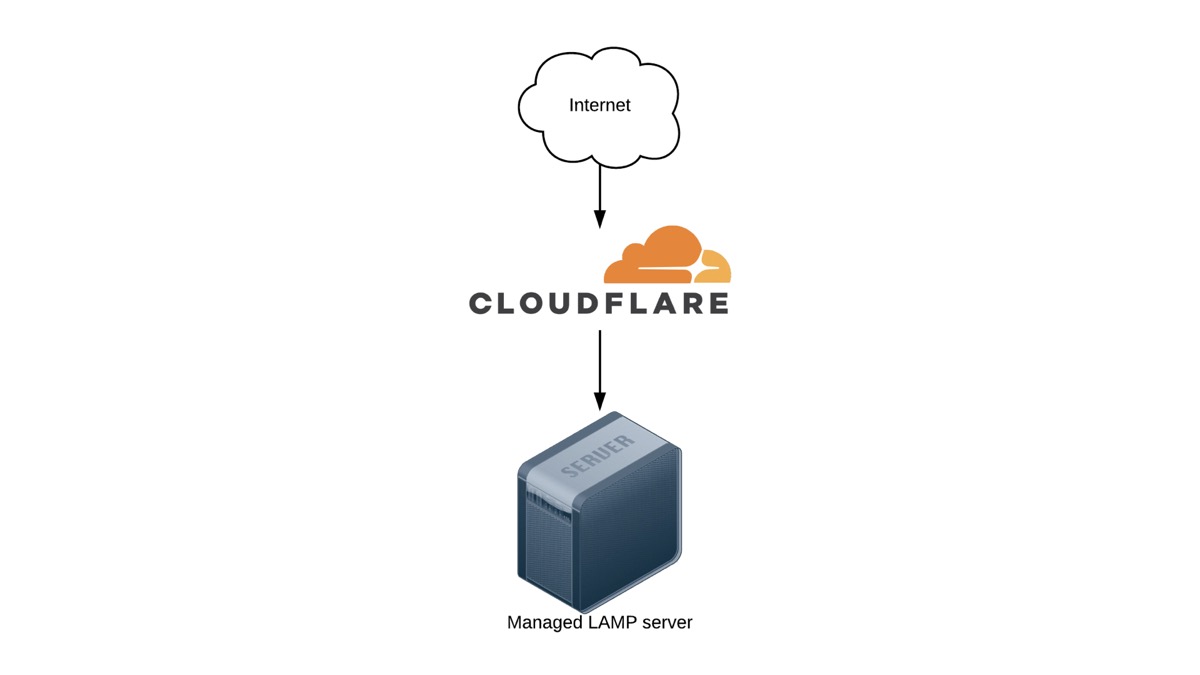
Just because you know how to produce excellent results with excellent tools doesn't mean you always have to use the 'best' and most powerful tools. You should also know when to use a simple hammer to nail in a few nails! This second architecture is better for this client, because it will cost less, be easier to maintain long-term, and won't require a full-time development team maintaining the infrastructure!

So know yourself. Learn and use new tools, but don't become an architecturenaut, always dreaming up and trying to build over-engineered solutions to simple problems!
That being said, not all the tools you'll need appear in the Cloud Native Landscape. Some of the tools I have in my toolbelt include:
YAGNI
I don't know how many times I've had to invoke YAGNI. That is, "You Ain't Gonna Need It!" It's great that you aspire to have your site get as much traffic as Facebook. But that doesn't mean you should architect it like Facebook does. Don't build fancy, complex automations and flexible architectures until you really need them. It saves you money, time, and sometimes it can even save a project from going completely off the rails!
Much like the gold plating on the hammer I was holding earlier, extra features that you don't need are a waste of resources, and may actually make your project worse off.
Andon board
In researching motivations behind some Agile practices, I came across an interesting book about lean manufacturing, The Machine that Changed the World. A lot of the ideas you may hear and even groan about in Agile methodology, and even DevOps, come from the idea of lean manufacturing.
One of the more interesting ideas is the andon board, a set of displays visible to every single worker in Toyota's manufacturing plant. If there's ever a problem or blockage, it is displayed on that board, and workers are encouraged to 'swarm the problem' until it is fixed—even if it's in a different part of the plant. The key is understanding that problems should not be swept aside to be dealt with when you have more time. Instead, everyone on the team must be proactive in fixing the problem before it causes a plant-wide failure to produce.
Time to Drupal
I did a blog post after DrupalCon last year discussing how different local Drupal development environments have dramatically different results in my measurement of "Time to Drupal". That is, from not having it downloaded on your computer, to having a functional Drupal environment you can play around with, how long does it take?
If it takes you more than 10 minutes to bring up your local environment, you should consider ways to make that process much faster. Unless you have a multi-gigabyte database that's absolutely essential for all development work (and this should be an exceedingly rare scenario), there's no excuse to spend hours or days onboarding a new developer, or setting up a new computer when your old one dies!
Dev to Prod
Similarly, how long does it take, once a feature or bugfix has been deployed somewhere and approved, for it to be deployed to production? Does this process take more than a day? Why? Are you trying to batch multiple changes together into one larger deployment?
The DevOps Handbook has some good advice about this:
"one of the best predictors of short lead times was small batch sizes of work"
—The DevOps Handbook
And wouldn't you know, there's a lean term along this theme: Takt time, or the average amount of time it takes between delivering units of work.
If you batch a bunch of deployments together instead of delivering them to production as they're ready, you'll have a large Takt time, and this means you can't quickly deliver value to your end users. You want to reduce that time by speeding up your process for getting working code to production.
Conclusion
Those tools might not be the tools you were thinking I'd mention, like DevShop, Drupal VM, Lando, Docker, or Composer. But in my mind, if you want to implement DevOps in the real world, those tools might be helpful as implementation details, but you should spend more time thinking about real world DevOps tools: better process, better communication, and better relationships.
If you do that, you will truly end up making people happier while making apps better.
Thank you.
Resources mentioned in the presentation
- The DevOps Handbook
- The Phoenix Project (if you're stuck in bureaucratic hell)
- Refactoring
- The Mythical Man-Month (not strictly mentioned here but a great read about team dynamics for software development)
- The Machine that Changed the World
Comments
Hi, you look happy. How is your recovery going?
It's going very well! Still not back to 100%, but I'm feeling the best I felt since mid-to-late 2017. #noColonStillRollin
Should I use Kubernetes with Drupal for a website (small site, not very much visits) that are for global users (mostly China, one server in China, and plus one server in USA maybe).
What is your companion book's Name about Kubernetes ? and do you have some book recommendations for Kubernetes (especially work for Drupal)?
I would stick to a simpler architecture for a small site—it would be better to use a CDN like CloudFlare or AWS CloudFront to make global access/latency faster. It's still extremely difficult (IMO) to use Kubernetes in a globally-distributed/multi-cluster setup.
My Kubernetes book (still working on the first few chapters): Ansible for Kubernetes.
Thank you for a well-thought out blog post on the who, what and how of DevOps. Presenting on DevOps is a funny thing. I’ve attended presentations that trip up when defining what DevOps is. The presenter’s meta-narrative becomes so unwieldy and far-fetched that I forget why I’m in the room. You’ve done better here. Your actionable items go further than guidances I’ve seen elsewhere.
I struggle with the part of your DevOps definition as something that “makes people happier,” which is too vague and overarching. I agree that integrating processes, tools, and people make for a more effective production and creative environment. This, in turn, might help those team members to become happier. I’d say a work process that helps make “people happier” is quite the scope creep and an impractical metric to track.
Time to development and time to production sound like solid metrics to track. Dashboards are harder to define as well as identifying the tools that help reduce the overhead of maintaining the dashboard data to a dull roar. Is YAGNI measurable? Maybe? Anyhow, you’ve given a lot for this manager to think about.
One of the few ways that I can think of that measures happiness well is a practice I've been able to do with some of my teams: every time we have a retrospective (or some other regular weekly or bi-weekly meeting), everyone gives a 'temperature'. We use either a 1-5 or 1-10 scale.
10 is feeling on top of the world, like they're amazing and the world is great, and they're happy on the project. 1 is they just had a major loss in their family, they hate their job, or something major is bothering them.
Most people fall within 3-8 or so, but if you track this metric over months (or even better, years), and if your team has some level of trust, then you can see trends... if the average falls below a 5 (or just has a downward trend), it's not a great sign. If the average is always improving you either have a lot of liars, or the team is actually happier (e.g. they are satisfied with the challenge of their work, but not overwhelmed, and they are less stressed).
Also, the most important thing is members should feel safe saying they're a 1 or 2 or some other low number—this should not trigger an immediate conversation, it should be perfectly acceptable, and they can follow up with someone at their discretion (sometimes you just have a bad day).